Hoy vamos a volver sobre el tema del sobremuestreo. Respondemos a un lector, Roberto, que hace mucho tiempo planteó una duda al respecto. La duda se puede resumir: En un modelo logístico, ¿equivale entrenar un modelo con las observaciones sobremuestreadas a entrenar el modelo poniendo un peso a cada observación? Esta cuestión nunca me la había planteado. Siempre había realizado un sobremuestreo de las observaciones adecuando la población de casos negativos a la población de casos positivos. Si estás habituado a trabajar con Enterprise Miner de SAS es habitual asignar pesos a las observaciones para realizar el proceso de sobremuestreo. ¿Obtendremos distintos resultados?
Vamos a estudiar un ejemplo con SAS y analizar que está pasando:
*REGRESION LOGISTICA PERFECTA;
data logistica;
do i=1 to 100000;
x=rannor(8);
y=rannor(2);
prob=1/(1+exp(-(-5.5+2.55*x-1.2*y)));
z=ranbin(8,1,prob);
output;
end;
drop i;
run;
title "Logistica con un 5% aprox de casos positivos";
proc freq data=logistica;
tables z;
quit;
Tenemos un conjunto de datos SAS con 100000 observaciones aleatorias y dos variables independientes (x e y) con distribución normal y creamos una variable dependiente z que toma valores 0 o 1 en función de la probabilidad de un modelo logístico. Es decir, podemos modelizar una regresión logística perfecta con parámetros Z=5.5 – 2.55x + 1.2y Esta distribución nos ofrece aproximadamente un 5% de casos positivos. A ser un modelo logístico perfecto si realizamos la regresión lineal sobre los datos obtendremos:
title "Ajuste de logistica perfecto";
proc logistic data=logistica;
model z=x y;
quit;
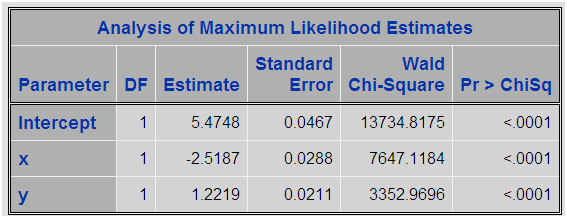
Un modelo casi perfecto. Ahora vamos a realizar un proceso de sobremuestreo y analizar los parámetros:
*MUESTRA ALEATORIA CON REEMPLAZAMIENTO;
PROC SURVEYSELECT DATA=logistica (where=(z=1))
OUT=unos METHOD=URS N=50000 outhits ;
RUN;
*MUESTRA ALEATORIA SIMPLE;
PROC SURVEYSELECT DATA=logistica (where=(z=0))
OUT=ceros METHOD=SRS N=50000;
RUN;
data logistica2;
set unos (drop=numberhits) ceros;
run;
title "Ajuste a logistica con sobremuestreo";
proc logistic;
model z=x y;
quit;
Con el PROC SURVEYSELECT en un primer paso realizamos un muestreo con reemplazamiento para los casos positivos, posteriormente realizamos un muestreo aleatorio simple para los casos sin evento. Unimos ambas tablas y realizamos el PROC LOGISTIC para la nueva tabla con proporción 50% de unos y 50% de ceros:
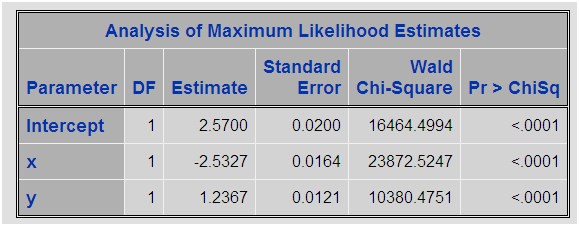
Sólo ha variado el término independiente que se ha reducido a la mitad (más o menos). [A ver si alguien puede contar porqué se está produciendo este hecho]. Pero lo que más nos interesa es saber qué sucede si en vez de realizar el sobremuestreo asignamos pesos a las observaciones. ¡Ojo! No vamos a crear una variable offset en el modelo, vamos a asignar un peso a cada registro de la tabla, eso es un tema interesante que necesitaría otra entrada en el blog. El proceso de creación de esta variable peso es muy sencillo:
*AHORA VAMOS A ASIGNAR PESOS A LAS OBSERVACIONES;
proc sql noprint;
select sum(z)/count(*) into: pct
from logistica;
quit;
data logistica3;
set logistica;
if z=0 then peso=0.5/(1-&pct.);
else peso=0.5/&pct.;
run;
proc means data=logistica3 sum nway;
class Z;
var peso;
run;
title "Ajuste a logistica con pesos";
proc logistic data=logistica3;
model z=x y;
weight peso;
quit;
El peso consiste en dividir el porcentaje que deseamos entre el porcentaje real, así de sencillo, al final la suma del peso de las observaciones será igual al total de las observaciones. En el PROC LOGISTIC añadimos la sentencia WEIGHT para indicar que variable contiene el peso. El resultado de este modelo es:
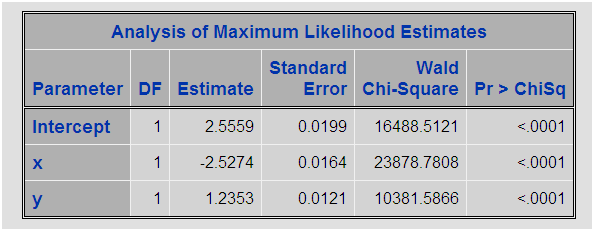
Prácticamente el mismo modelo que hemos obtenido con el proceso de sobremuestreo. Así que estamos en disposición de asegurar que asignar pesos a las observaciones y emplear estos pesos para realizar los modelos de regresión logística equivale a realizar el sobremuestreo. Reiterando, no es lo mismo que emplear una variable offset en el modelo. Con esto espero que antes de realizar complejos procesos de muestreo para detectar patrones con modelos de regresión logística asignéis pesos a registros.
Ahora queda extrapolar estas conclusiones a otros modelos. Saludos.
Raúl. En mi ignorancia,¿por qué es necesario el sobremuestreo?¿afecta a las estimaciones? Un pequeño ejemplo con R me lo aclararia. Jeje. Un saludo
Hola Raúl. Disculpa mi ignorancia. ¿por qué es necesario? el sobremuestreo? ¿afecta a las estimaciones? Un ejemplo con R sería genial que yo de SAS ni idea. Saludos
Hola, en realidad este ejemplo sirve para demostrar que matemáticamente no tiene influencia alguna en la regresión logística. Así que no es necesario. Mira los parámetros resultantes.
Sin embargo es más habitual cuando se utilizan árboles o redes neuronales y el evento tiene un porcentaje ridículo. La utilidad del sobremuestreo en árboles me la he guardado para otro día y lo haré con R por supuesto.
Escribiendo esto si me he encontrado con la diferencia entre las variables offset y el peso de las observaciones, un tema evidente pero interesante.
Buenas.
El problema que tan bien ilustras empíricamente está tratado teóricamene en variedad de artículos, incluyendo las propiedades de los estimadores. El papel pionero es: «Estimation of choice probabilities from choice based samples» http://www.jstor.org/discover/10.2307/1914121?uid=3737952&uid=2129&uid=2&uid=70&uid=4&sid=47698805145167
Un saludo
Gracias a los dos. Me va a ser muy útil, en cuánto tenga un rato, voy a ver si replico tu ejemplo en R ..
Saludos..
Hola Raúl,
Una diferencia entre usar pesos y «sobremuestrear» podría darse en el caso de que no quieras «aumentar el número de unos», si no «reducir el número de ceros» hasta conseguir el mismo ratio? Aunque eso igual no se debería llamar «sobremuestrear» si no «inframuestrear», ¿no?
Por otro lado, no veo por qué «este ejemplo sirve para demostrar que [el sobremuestreo] matemáticamente no tiene influencia alguna en la regresión logística». Si el modelo inicial no fuera perfecto, ¿el sobremuestro no lo podría mejorar?
Hola Nacho, la primera cuestión se puede cambiar a sobremuestrear los ceros.
La segunda cuestión es la que me ha impedido publicar esta entrada desde hace tiempo y de hecho paso de puntillas. Matemáticamente el sobremuestreo no debería afectar al modelo logístico sin embargo, en la práctica, tanto tú como yo sabemos que el sobremuestreo nos ayuda a encontrar modelos con un mejor comportamiento.
Y eso es lo que no entiendo. ¿Cómo es posible que el sobremuestreo mejore la estimación de un modelo logístico si matemáticamente no debería influir? Pues a ti y a mi nos ha pasado y en mi caso concreto más de una vez.
Todos los temas que puedan llegar a definir una logistica exacta y correcta, son positivos para lograr buenos resultados.
Hola Raul, hablaste de la utilidad del sobremuestreo en árboles y redes neuronales. Yo considero que es la más útil, últimamente me he encontrado con problemas donde podría aplicarse, pero necesito argumentos para justificar el sobremuestreo.
En mi caso particular estamos considerando coger el censo de los casos positivos, dado que son muy excasas y una muestra de los casos negativos.
Estoy ansioso esperando tu post.
Hola David, este tema lo tengo un poco parado. En árboles de decisión si parece tener justificación, pero hay que demostrarlo. En redes neuronales tengo mis dudas.
Hola a todos.
En este ejemplo se ha hecho y muestreo separado, y se ha realizado la regresión logística por máxima verosimilitud. Pero los estamadores máximo verosímiles se obtienen bajo la suposición de que la variable dependiente sigue una distribución de Bernoulli, lo cual no se cumple en el sobremuestreo. El efecto de violar esta suposición solo afecta al término independiente del modelo. En realidad lo que se ha ajustado es el «seudo modelo»:
logit(p*)=ln(p1*pi1/p0*pi0)+c+a*x+b*y
con p* la probabilidad del modelo sesgado y siendo pi0 y pi1 las proporciones poblacionales de los evento 0 y 1 respectivamente, y p0, p1 las muestrales. Por supuesto si queremos las probabilidades predichas tenemos que hacer la corrección por sobremuestreo, pero si lo único que nos interesa es comprender la relación entre las variables independiente y dependiente o generar un rango de los elementos de la población, no es hace falta corrección.
Pregunta del millón. ¿Qué corrección utilzáis para «deshacer el sobremuestreo» en la predicción del modelo? Hay por ahí una fórmula que parece ser la que usa Enterprise Miner…
Otra pregunta menos relevante… ¿Por qué en España llamamos sobremuestreo a lo que los americanos llaman undersampling?
Los americanos los llaman oversampling.
Esto se denomina oversampling.
Tu pregunta Fernando es mejor de lo que me esperaba. No tengo ni idea. Lo hace el Miner…
De todos modos esta entrada justifica la «no necesidad» de utilizar el sobremuestreo para modelos de regresión logística. A ver si nos vamos a dispersar.
Fernando, esta es una buena explicación de como hacer la corrección de sobremuestreo:
http://support.sas.com/kb/22/601.html
A ver pregunta: ¿Qué diferencia hay entre weight y offset? Parece evidente pero… Si no responde nadie haré una entrada sobre ello. Bueno, la haré de todos modos.
Ups, leí en diagonal y no vi que también había un surveyselect para los «unos» con n=50000, pensaba que era el «cojo todos los unos y me quedo con x% de ceros aleatorios» al que casi todo el mundo que conozco llama «sobremuestreo»
Fernando en este caso se ha obtenido una muestra que tiene el mismo tamaño que la población lo cual no tiene sentido. Saludos