La clasificación por k vecinos más cercanos es EL MÉTODO supervisado no paramétrico. El KNN, si empleamos las siglas en inglés, clasifica las observaciones en función de su probabilidad de pertenecer a uno u otro grupo, en el video que encabeza la entrada queda muy bien explicado. El caso es que tenemos la posibilidad de realizar esta clasificación con SAS STAT y el PROC DISCRIM y me parece interesante dedicarle unas líneas. Hace años ya hablamos de segmentación con SAS y vamos a emplear los mismos datos para ilustrar esta entrada. Primero generamos un conjunto de datos con datos simulados de 3 esferas que clasificamos en 3 grupos:
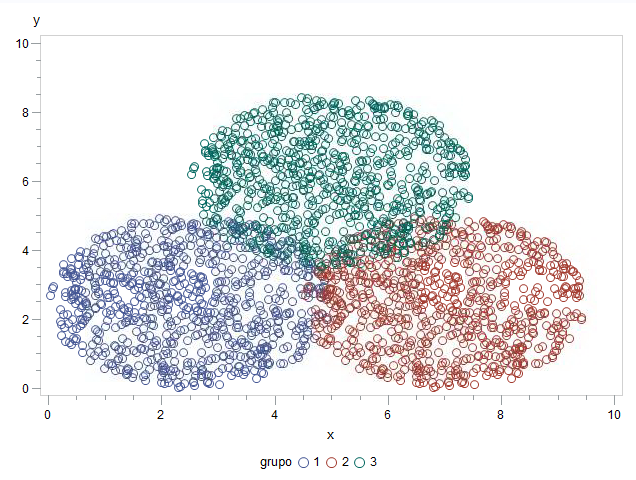
data pelota; do i = 1 to 1000; a=0; b=5; x = a+(b-a)*ranuni(34); a=0; b=5; y = a+(b-a)*ranuni(14); grupo=1; distancia = sqrt(((x-2.5)**2)+((y-2.5)**2)); if distancia < 2.5 then output; end; run; data pelota1; set pelota; grupo=1; run; data pelota2; set pelota; x = x+4.5; grupo=2; run; data pelota3; set pelota; x = x+2.5; y = y+3.5; grupo=3; run; data datos; set pelota1 pelota2 pelota3; run; proc gplot data=datos; plot y * x = grupo; run;quit;
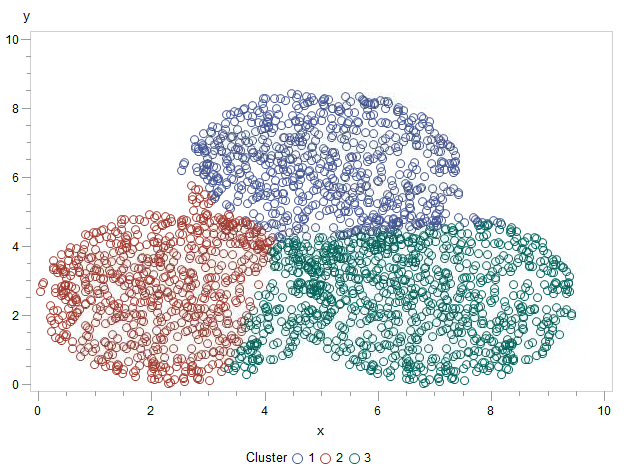
Si realizamos un análisis mediante k-means sin asignar centroides obtenemos esta clasificación:
proc fastclus data=datos maxclusters=3 out=datos2; var x y; quit; proc gplot data=datos2; plot y * x = cluster; run;quit;
Ya vimos que había algunos problemas por la asignación aleatoria de centroides. Este problema lo podemos solventar empleando clasificación por KNN a partir del PROC DISCRIM:
data entreno testeo; set datos; if ranuni(7)>=0.5 then output entreno; else output testeo; run; proc discrim data = entreno test = testeo testout = puntuacion method = npar k = 5 Crossvalidate; class grupo; var x y; run; proc gplot data=puntuacion; plot y * x = _into_; run;quit;
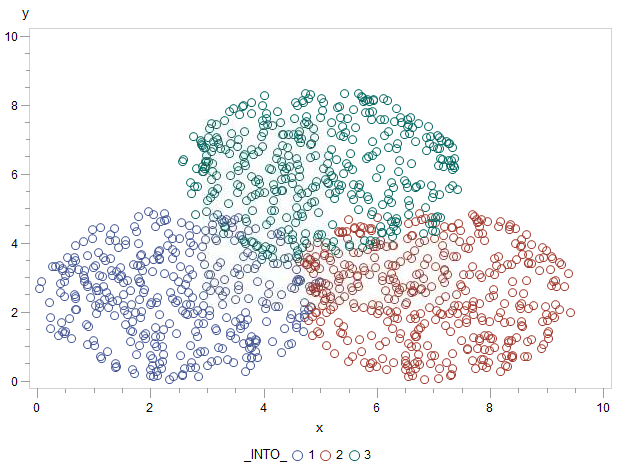
El resultado es muy satisfactorio como se puede ver en la figura y la sintaxis del PROC DISCRIM tampoco es muy compleja, necesitamos conjunto de datos de test y validación y generamos un dataset de salida que denominamos puntuación en method especificamos que la clasificación la llevamos a cabo con un método no paramétrico y en ese momento necesitamos especificar la k que es el número de vecinos que vamos a evaluar para clasificar cada observación y evaluamos como funciona nuestra clasificación mediante validación cruzada. El resultado de esta clasificación no paramétrica lo podemos ver en el gráfico, el resultado muy satisfactorio. Es necesario tratar con más cariño el número de vecinos (k) pero esta tarea la dejo pendiente para otro momento porque sería interesante automatizarla. El caso es que bajo mi punto de vista sigo prefiriendo el uso de k medias pero knn puede ayudarnos a seleccionar las semillas iniciales para nuestra clasificación por k medias:
proc summary data=puntuacion nway; class grupo; output out=medias (keep= x y) mean(x)= mean(y)=; quit; proc fastclus data=datos maxclusters=3 out=datos3 seed=medias; var x y; quit; proc gplot data=datos3; plot y * x = cluster; run;quit;
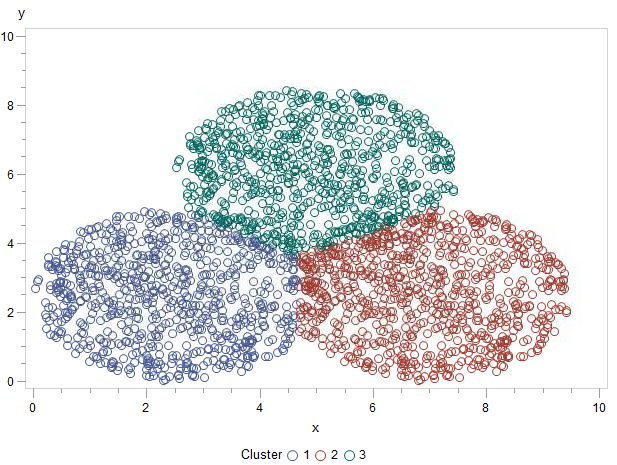
Este análisis si arroja resultados muy interesantes. Saludos.