El proposito del análisis de conglomerados (cluster en terminología inglesa) es el agrupar las observaciones de forma que los datos sean muy homogéneos dentro de los grupos (mínima varianza) y que estos grupos sean lo más heterogéneos posible entre ellos (máxima varianza). De este modo obtenemos una clasificación de los datos multivariante con la que podemos comprender mejor los mismos y la población de la que proceden. Podemos realizar análisis cluster de casos, un análisis cluster de variables o un análisis cluster por bloques si agrupamos variables y casos. El análisis cluster se puede utilizar para:
• La taxonomía, agrupar especies naturales.
• Para el marketing, clasificar consumidores tipo.
• Medicina, clasificar seres vivos con los mismos síntomas y características patológicas.
• Técnicas de reconocimiento de patrones.
• Formar grupos de pixels en imágenes digitalizadas enviadas por un satélite desde un planeta para identificar los terrenos.
• …
Como siempre la metodología del análisis y la programación con R la vamos a estudiar mediante un ejemplo.
Ejemplo Cluster.1:
Partimos de los precios de las viviendas en España desde el último trimestre de 2007 al último trimestre de 2008 por provincia y municipio, trataremos de agrupar ciudades. Los datos los tenemos en formato Excel y han sido descargados del Ministerio de la Vivienda, por ello necesitamos leer los datos con el paquete RODBC (que no tenemos instalado):
install.packages("ROdBC") #instalamos el paquete si no lo tenemos
--- Please select a CRAN mirror for use in this session ---
Warning message:
package ‘ROdBC’ is not available
install.packages("RODBC")
probando la URL 'http://cran.es.r-project.org/bin/windows/contrib/2.8/RODBC_1.2-5.zip'
Content type 'application/zip' length 194962 bytes (190 Kb)
URL abierta
downloaded 190 Kb
package 'RODBC' successfully unpacked and MD5 sums checked
The downloaded packages are in
C:\Documents and Settings\Configuración local\Temp\RtmpiQDtqf\downloaded_packages
updating HTML package descriptions
library(RODBC) #llamamos al paquete instalado
setwd("c:/raul") #establecemos el directorio de trabajo
tabla<-odbcConnectExcel("vivienda.xls") #creamos el objeto tabla con el Excel de datos
datos<-sqlFetch(tabla,"Hoja1") #objeto que contiene los datos de la Hoja1
odbcClose(tabla) #cerramos la conexión con el libro Excel
Un buen ejemplo para conocer como instalar paquetes en R con la función INSTALLL. Y un buen ejemplo para importar datos desde Excel a R. Con estos pasos ya tenemos un conjunto de datos con las siguientes variables:
• Provincia
• Municipio
• Viv_2anios2007_1
• Viv_mas2anios2007_1
• Tas_2anios2007_1
• Tas_mas2anios2007_1
• Viv_2anios2008_1
• Viv_mas2anios2008_1
• Tas_2anios2008_1
• Tas_mas2anios2008_1
• Viv_2anios2008_2
• Viv_mas2anios2008_2
• Tas_2anios2008_2
• Tas_mas2anios2008_2
• Viv_2anios2008_3
• Viv_mas2anios2008_3
• Tas_2anios2008_3
• Tas_mas2anios2008_3
• Viv_2anios2008_4
• Viv_mas2anios2008_4
• Tas_2anios2008_4
• Tas_mas2anios2008_4
Disponemos de la provincia, el municipio (municipios con más de 25.000 habitantes) y variables VIV que hacen referencia al precio de la vivienda en €/m2 y variables TAS que hacen referencia al número de tasaciones. Estas variables a su vez pueden ser 2ANIOS si tienen menos de 2 años (vivienda nueva) o MAS2ANIOS si son viviendas antiguas. No tiene mucho sentido agrupar por variables que miden un importe o un número, es más interesante realizar el análisis cluster sobre variaciones entre trimestres. Por esto el conjunto de datos requiere un tratamiento previo para calcular el % de diferencia de precio y del número de tasaciones:
attach(datos) #Creamos un objeto para cada diferencia y posteriormente unimos
dif_Viv_2anios_1=Viv_2anios2007_1/Viv_2anios2008_1-1
dif_Viv_2anios_2=Viv_2anios2008_1/Viv_2anios2008_2-1
dif_Viv_2anios_3=Viv_2anios2008_2/Viv_2anios2008_3-1
dif_Viv_2anios_4=Viv_2anios2008_3/Viv_2anios2008_4-1
dif_Viv_mas2anios_1=Viv_mas2anios2007_1/Viv_mas2anios2008_1-1
dif_Viv_mas2anios_2=Viv_mas2anios2008_1/Viv_mas2anios2008_2-1
dif_Viv_mas2anios_3=Viv_mas2anios2008_2/Viv_mas2anios2008_3-1
dif_Viv_mas2anios_4=Viv_mas2anios2008_3/Viv_mas2anios2008_4-1
dif_Tas_2anios_1=Tas_2anios2007_1/Tas_2anios2008_1-1
dif_Tas_2anios_2=Tas_2anios2008_1/Tas_2anios2008_2-1
dif_Tas_2anios_3=Tas_2anios2008_2/Tas_2anios2008_3-1
dif_Tas_2anios_4=Tas_2anios2008_3/Tas_2anios2008_4-1
dif_Tas_mas2anios_1=Tas_mas2anios2007_1/Tas_mas2anios2008_1-1
dif_Tas_mas2anios_2=Tas_mas2anios2008_1/Tas_mas2anios2008_2-1
dif_Tas_mas2anios_3=Tas_mas2anios2008_2/Tas_mas2anios2008_3-1
dif_Tas_mas2anios_4=Tas_mas2anios2008_3/Tas_mas2anios2008_4-1
objects()
[1] "datos" "dif_Tas_2anios_1" "dif_Tas_2anios_2" "dif_Tas_2anios_3" "dif_Tas_2anios_4" "dif_Tas_mas2anios_1"
[7] "dif_Tas_mas2anios_2" "dif_Tas_mas2anios_3" "dif_Tas_mas2anios_4" "dif_Viv_2anios_1" "dif_Viv_2anios_2" "dif_Viv_2anios_3"
[13] "dif_Viv_2anios_4" "dif_Viv_mas2anios_1" "dif_Viv_mas2anios_2" "dif_Viv_mas2anios_3" "dif_Viv_mas2anios_4" "dif1"
[19] "tabla"
Ahora vamos a unir los 16 objetos creados con la provincia y el municipio empleando las funciones SUBSET y CBIND:
datos<-data.frame(datos)
analisis<-subset(datos,select=c(Provincia,Municipio))
analisis<-(cbind(analisis,
dif_Viv_2anios_1 ,
dif_Viv_2anios_2 ,
dif_Viv_2anios_3 ,
dif_Viv_2anios_4 ,
dif_Viv_mas2anios_1 ,
dif_Viv_mas2anios_2 ,
dif_Viv_mas2anios_3 ,
dif_Viv_mas2anios_4 ,
dif_Tas_2anios_1 ,
dif_Tas_2anios_2 ,
dif_Tas_2anios_3 ,
dif_Tas_2anios_4 ,
dif_Tas_mas2anios_1 ,
dif_Tas_mas2anios_2 ,
dif_Tas_mas2anios_3 ,
dif_Tas_mas2anios_4 ))
Ya tenemos una tabla de entrada para nuestro análisis pero nos encontramos con múltiples valores perdidos. Para este análisis no vamos a tener en cuenta los valores perdidos. Para eliminar aquellas observaciones que tienen NA empleamos la función NA.OMIT:
analisis.ok<-na.omit(analisis)
analisis.ok<-data.frame(analisis.ok)
nrow(analisis.ok)/nrow(analisis) # Estudiamos cuantas obs eliminamos
[1] 0.7031802
Eliminamos un 30% de las observaciones. Escierto que son muchas y deberíamos hacer un tratamiento con ellas, pero de momento es preferible eliminarlas. Ya disponemos de un data.frame adecuado para calcular la matriz de distancias sobre la que realizaremos el análisis cluster con R para determinar el número de grupos que formaremos:
> distancias<-dist(analisis.ok)
Warning message:
In dist(analisis.ok) : NAs introducidos por coerción
> cluster.1<-hclust(distancias,method="average")
> summary(cluster.1)
Length Class Mode
merge 396 -none- numeric
height 198 -none- numeric
order 199 -none- numeric
labels 199 -none- character
method 1 -none- character
call 3 -none- call
dist.method 1 -none- character
> plot(cluster.1)
Vemos que a la función DIST le introducimos valores carácter y tenemos el warning “NAs introducidos por coerción” (una de las frases de búsqueda de Google que más visitas trae a AyD). Con la matriz de distancias realizamos el análisis jerárquico de conglomerados por el método de la media y necesitamos establecer el número de grupos a elegir y para ello la función PLOT nos imprime el dendograma de nuestro análisis como vemos en la siguiente figura:
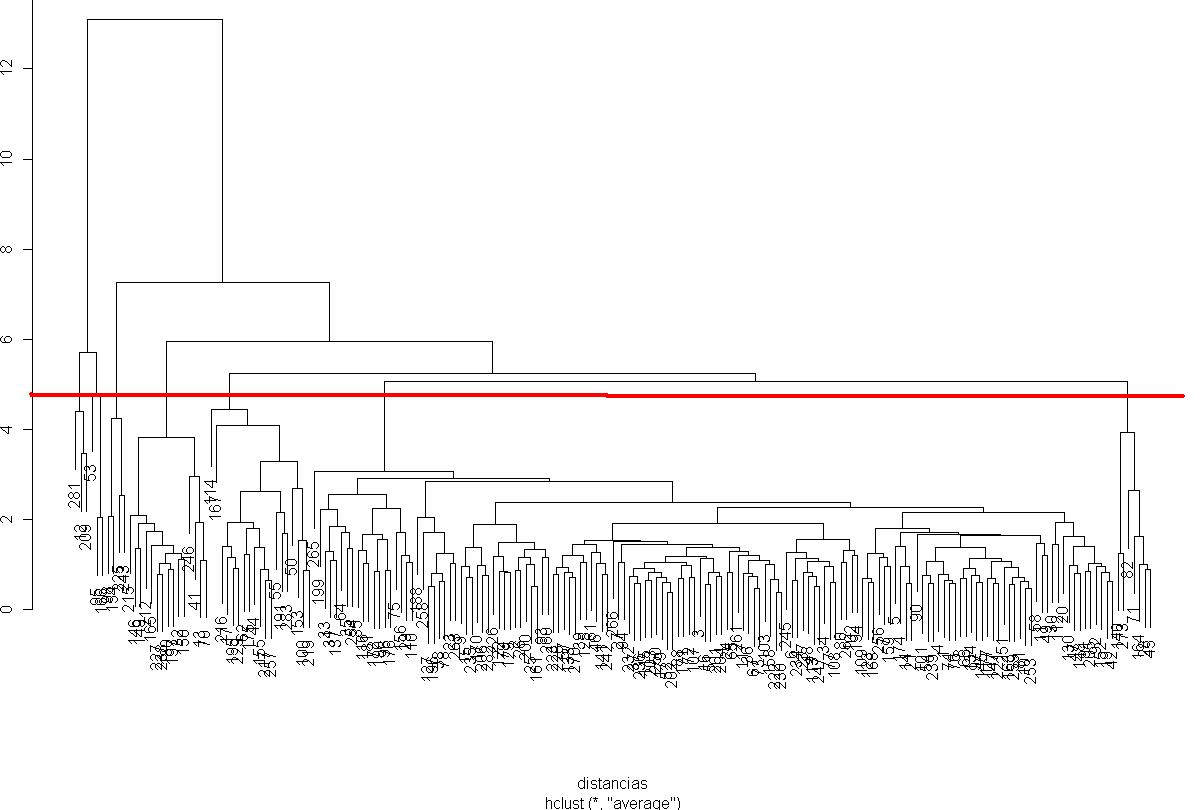{kind=link}

He marcado manualmente el gráfico resultante y considero que 6 grupos son los adecuados. Aunque parece que 2 grupos son muy numerosos y el resto mucho menos, el corte queda sujeto a la interpretación del analísta. Ya podemos realizar un análisis no jerárquico para asignar a cada observación un cluster:
cluster.1.nojerar<-kmeans(distancias,6)
asignacion<-data.frame(cluster.1.nojerar$cluster)
Hemos creados el objeto asignacion que asigna a cada observación el cluster resultante del análisis no jerárquico. Este objeto le unimos con analsis.ok y podemos analizar como se ha comportado el agrupamiento:
analisis.ok<-cbind(analisis.ok,asignacion)
colnames(analisis.ok)
[1] "Provincia" "Municipio" "dif_Viv_2anios_1" "dif_Viv_2anios_2" "dif_Viv_2anios_3"
[6] "dif_Viv_2anios_4" "dif_Viv_mas2anios_1" "dif_Viv_mas2anios_2" "dif_Viv_mas2anios_3" "dif_Viv_mas2anios_4"
[11] "dif_Tas_2anios_1" "dif_Tas_2anios_2" "dif_Tas_2anios_3" "dif_Tas_2anios_4" "dif_Tas_mas2anios_1"
[16] "dif_Tas_mas2anios_2" "dif_Tas_mas2anios_3" "dif_Tas_mas2anios_4" "cluster.1.nojerar.cluster"
Vemos que por defecto el nombre que le asigna a la variable es CLUSTER.1.NOJERAR.CLUSTER, largo y que puede ser difícil de manejar. Veamos unas instrucciones de R para renombrar variables en un data.frame:
> length(colnames(analisis.ok))
[1] 19
> names(analisis.ok)[19]<-"cluster" #renombramos la última variable
> colnames(analisis.ok) #vemos de nuevo las variables
[1] "Provincia" "Municipio" "dif_Viv_2anios_1" "dif_Viv_2anios_2" "dif_Viv_2anios_3"
[6] "dif_Viv_2anios_4" "dif_Viv_mas2anios_1" "dif_Viv_mas2anios_2" "dif_Viv_mas2anios_3" "dif_Viv_mas2anios_4"
[11] "dif_Tas_2anios_1" "dif_Tas_2anios_2" "dif_Tas_2anios_3" "dif_Tas_2anios_4" "dif_Tas_mas2anios_1"
[16] "dif_Tas_mas2anios_2" "dif_Tas_mas2anios_3" "dif_Tas_mas2anios_4" "cluster"
Ahora trabajaremos con la variable cluster del objeto analisis.ok. Hemos cambiado con NAMES el elemento 19 del vector de nombres del data.frame análisis.ok. Y procede estudiar una a una las variables con las que se ha realizado el agrupamiento no jerárquico. Pero lo principal es el tamaños de los grupos:
tapply(analisis.okdif_Viv_2anios_1,analisis.okcluster,length)
1 2 3 4 5 6
14 89 8 5 64 19
Empleamos la función TAPPLY con length. Es el grupo 2 el más numeroso en contraposición del 4 y el 3 que aglutinan muy pocas ciudades.Veamos las medias de las variables en estudio por cluster:
med_viv_nuevas1<-data.frame(tapply(analisis.okdif_Viv_2anios_1,analisis.okcluster,mean))
med_viv_nuevas2<-data.frame(tapply(analisis.okdif_Viv_2anios_2,analisis.okcluster,mean))
med_viv_nuevas3<-data.frame(tapply(analisis.okdif_Viv_2anios_3,analisis.okcluster,mean))
med_viv_nuevas4<-data.frame(tapply(analisis.okdif_Viv_2anios_4,analisis.okcluster,mean))
medias_nuevas<-cbind(med_viv_nuevas1,med_viv_nuevas2,med_viv_nuevas3,med_viv_nuevas4)
trimestres<-c('T1','T2','T3','T4')
names(medias_nuevas)<-trimestres
medias_nuevas
T1 T2 T3 T4
1 0.01944685 -0.01355665 0.018865264 0.04104020
2 -0.01582340 0.01500281 0.009886183 0.04982607
3 -0.04104529 0.00987412 0.019035202 0.12528055
4 -0.01596602 -0.02644902 -0.024867577 0.06581857
5 -0.01201724 0.01307219 0.021198929 0.04630275
6 0.03923795 -0.02923384 0.007707944 0.03984843
Vemos que los municipios del grupo 2 han seguido un precio al alza de la vivienda de la vivienda con menos de 2 años durante 2008. Destacar del grupo 3 el fuerte alza de los precios del metro cuadrado en el último trimestre de 2008. Continuemos con el resto:
> med_viv_antig1<-data.frame(tapply(analisis.okdif_Viv_mas2anios_1,analisis.okcluster,mean))
> med_viv_antig2<-data.frame(tapply(analisis.okdif_Viv_mas2anios_2,analisis.okcluster,mean))
> med_viv_antig3<-data.frame(tapply(analisis.okdif_Viv_mas2anios_3,analisis.okcluster,mean))
> med_viv_antig4<-data.frame(tapply(analisis.okdif_Viv_mas2anios_4,analisis.okcluster,mean))
> medias_antig<-cbind(med_viv_antig1,med_viv_antig2,med_viv_antig3,med_viv_antig4)
> names(medias_antig)<-trimestres
> medias_antig
T1 T2 T3 T4
1 -0.0030822873 1.405480e-03 0.00644564 0.02491635
2 -0.0009577722 -3.109779e-05 0.01987918 0.02427171
3 -0.0213095131 -1.242472e-02 0.02757964 0.04139780
4 -0.0414540014 2.252411e-02 0.03583399 -0.01586075
5 -0.0001875384 1.105854e-02 0.02087253 0.03461745
6 -0.0119681455 6.223535e-03 0.01663899 0.04082545
Variaciones mucho menores para la vivienda antigua. Destacan las subidas del T4 de 2008 de los grupos 3 y 6. No parece ser el precio de la vivienda antigua una variable que agrupe los municipios. Comencemos con las tasaciones, altamente correlacionadas con el número de hipotecas concedidas:
> med_Tas_nuevas1<-data.frame(tapply(analisis.okdif_Tas_2anios_1,analisis.okcluster,mean))
> med_Tas_nuevas2<-data.frame(tapply(analisis.okdif_Tas_2anios_2,analisis.okcluster,mean))
> med_Tas_nuevas3<-data.frame(tapply(analisis.okdif_Tas_2anios_3,analisis.okcluster,mean))
> med_Tas_nuevas4<-data.frame(tapply(analisis.okdif_Tas_2anios_4,analisis.okcluster,mean))
> medias_tas_nuevas<-cbind(med_Tas_nuevas1,med_Tas_nuevas2,med_Tas_nuevas3,med_Tas_nuevas4)
> names(medias_tas_nuevas)<-trimestres
> medias_tas_nuevas
T1 T2 T3 T4
1 0.3698500 -0.3833617 4.8499558 -0.2756194
2 0.1148176 0.4225245 0.1308613 0.6512111
3 2.4076334 1.4537830 2.3622222 1.0231803
4 -0.1053196 0.9841216 -0.5170033 13.1657197
5 0.1595510 0.4026895 1.3760159 -0.2556378
6 0.3940025 0.4076382 -0.1091876 4.3910450
El grupo 3 se diferencia por el increíble aumento en el número de las tasaciones ¿problemas de promotoras? Los grupos 4 y 6 hacen lo mismo pero en el último trimestre, siendo el grupo 4 el que tiene un aumento del 1300%. El grupo 1 el aumento lo sufre en T3 y el 5 aunque también tiene un pico en T3 permanece más lineal. Veamos las viviendas de segunda mano:
> med_Tas_antig1<-data.frame(tapply(analisis.okdif_Tas_mas2anios_1,analisis.okcluster,mean))
> med_Tas_antig2<-data.frame(tapply(analisis.okdif_Tas_mas2anios_2,analisis.okcluster,mean))
> med_Tas_antig3<-data.frame(tapply(analisis.okdif_Tas_mas2anios_3,analisis.okcluster,mean))
> med_Tas_antig4<-data.frame(tapply(analisis.okdif_Tas_mas2anios_4,analisis.okcluster,mean))
> medias_tas_antig<-cbind(med_Tas_antig1,med_Tas_antig2,med_Tas_antig3,med_Tas_antig4)
> names(medias_tas_antig)<-trimestres
> medias_tas_antig
T1 T2 T3 T4
1 -0.02557859 -0.087051949 0.5432659 0.19370372
2 -0.01317325 -0.008149198 0.4967322 0.13825095
3 0.03115062 -0.021663724 0.5537521 0.08079852
4 -0.03787022 0.055274194 0.4559323 0.85411655
5 -0.04315876 -0.015918749 0.5278449 0.22220167
6 -0.08349683 0.020287214 0.6191541 0.31953932
Fuerte aumento en T3 y T4 para todos, destaca el grupo 4 muy por encima del resto y que además ya sufrió subidas en T2 ¿embargos?
Con estos resultados podemos describir los 6 grupos formados:
Cluster 1: Municipios muy estables pero con alguna promoción en apuros.
Cluster2: El grupo más numeroso, es muy estable también pero no sufren un aumento espectacular de las tasaciones de vivienda nueva que pueden ser propias de promotores incapaces de hacer frente a la crisis.
Cluster 3: Un grupo de 8 municipios donde sigue en aumento el precio de la vivienda y también tienen un aumento exponencial de las tasaciones de vivienda nueva, donde menos ha afectado la crisis.
Cluster 4: El más pequeño de todos. Tiene un descomunal aumento de las tasaciones de vivienda antigua y bajaron sus precios en T4. Puede ser donde más daño hace la crisis.
Cluster 5: Un grupo numeroso con un precio estable pero donde bajaron las tasaciones de viviendas nuevas. Son zonas donde el boom del ladrillo no fue tan intenso.
Cluster 6: El grupo que comenzó 2008 con subidas de precios en viviendas nuevas y bajada en antiguas. Tuvo muchas tasaciones de antiguas en T3 pero las nuevas bajaron. Zona de fuerte parón en la construcción pero sin parón económico.
Con ejemplos podríamos estudiar las conclusiones. Hasta aquí este post que no va en la línea de post cortos de AyD pero que sirve de introducción al análisis cluster con R. Vamos a trabajar al menos 3 ejemplos más porque este tipo de trabajos engloba muchos usos de funciones imprescindibles de conocer y manejar en R. Como siempre para dudas o sugerencias… rvaquerizo@analisisydecision.es
este analisis es utilizando la metodologia de k medias, como seria para los centros moviles???
hola una pregunta, estoy por presentar un trabajo y vi un paper donde en el cluster en un eje me muestra similaridad y en otro eje disimilaridad ambos verticales. Cuales serian los comandos para graficarlo. Muchas gracias.
Hola, por favor podrían dejar disponible de alguna manera el archivo Excel que utilizan para el análisis? Al ingresar al hipervínculo del ministerio de vivienda me lleva a un articulo de escorts en sevilla. También trate de buscar estos datos en google y en la pagina del ministerio de fomento, pero no los he logrado encontrar.
Les estaría enormemente agradecido. Saludos.