¿Qué variables son las más importantes para nuestro modelo de clasificación? Yo creo que muchos de vosotros os habréis encontrado con esta problemática. Hay muchas formas de solventarla, habitualmente empleamos aquellas variables que mejor pueden entender nuestras áreas de negocio. Es decir, hacemos segmentaciones en base al sexo y la edad sólo por no tener que explicar como hemos construido una variable artificial a alguien que no entiende lo que es una variable y mucho menos variable artificial. Pero hoy os quería plantear la utilización de métodos de random forest con R para medir la importancia de las variables cuantitativas, para variables cualitativas recomiendo otras formas que plantearé más adelante. El random forest es un método de clasificación basado en la realización de múltiples árboles de decisión sobre muestras de un conjunto de datos. Hacemos muchas clasificaciones con menos variables y menos observaciones y al final nos quedamos con un promedio de estas clasificaciones, esa sería la idea a grandes rasgos. La característica que hace de este método muy interesante es la posibilidad de incluir un gran número de variables input en nuestro modelo ya que no encontraremos relaciones lineales entre ellas y tampoco aparecerán relaciones debidas al azar.
Para ilustrar nuestro ejemplo con R vamos a emplear un conjunto de datos que podéis obtener obtener en este link. Es una serie de datos y modelos, nos quedaremos con el conjunto de datos au2_10000.csv que tiene 251 variables y 10.000 registros. Son una serie de datos preparados para el estudio de modelos de clasificación. En nuestro caso nos servirá para determinar las variables cuantitativas más influyentes sobre la variable dependiente. Como variables explicativas tenemos aquellas que comienzan con att y como variable dependiente tendremos class. En mi caso concreto he subido los datos a la BBDD con la ayuda de Kettle por lo que mi trabajo con R comienza con la lectura de estos datos:
#ACCESO A BBDD
library(RODBC)
con = odbcConnect("PostgreSQL30",case="postgresql")
datos = sqlQuery (con,"SELECT * FROM MODELOS.AU_TABLE")
summary(datos)
str(datos)
Recordamos que para conectarnos con R a Postgres empleamos la libería RODBC como ya hicimos mención en anteriores mensajes. Ya disponemos del objeto datos con sus 251 variables y 10.000 registros, si deseáis disponer de él podéis descargaros el archivo aquí. La intención es crear un ranking con las variables cuantitativas más relevantes en el modelo de clasificación. Lo primero que tenemos que hacer es crear un objeto con las variables cuantitativas que deseamos analizar:
#Eliminamos los factores de nuestro objeto
eliminados=NULL
for (i in 1:length(datos)-1){
if (class(datos[,i]) == "factor" ){eliminados<-rbind(eliminados,i)} }
datos2 = datos[,-eliminados]
head(datos2)
Recorremos las clases del objeto datos y eliminamos aquellas que son factores a excepción de class que será nuestra variable dependiente. Con este objeto realizamos nuestro proceso. Uno de los paquetes que podemos emplear es randomForest y un ejemplo de su uso podría ser:
#install.packages("randomForest")
library(randomForest)
modelo1 <- randomForest(class~.,data=datos2,
ntree=500,importance=TRUE,maxnodes=10,mtry=25)
#Creamos un objeto con las "importancias" de las variables
importancia=data.frame(importance(modelo1))
library(reshape)
importancia<-sort_df(importancia,vars='MeanDecreaseGini')
importancia
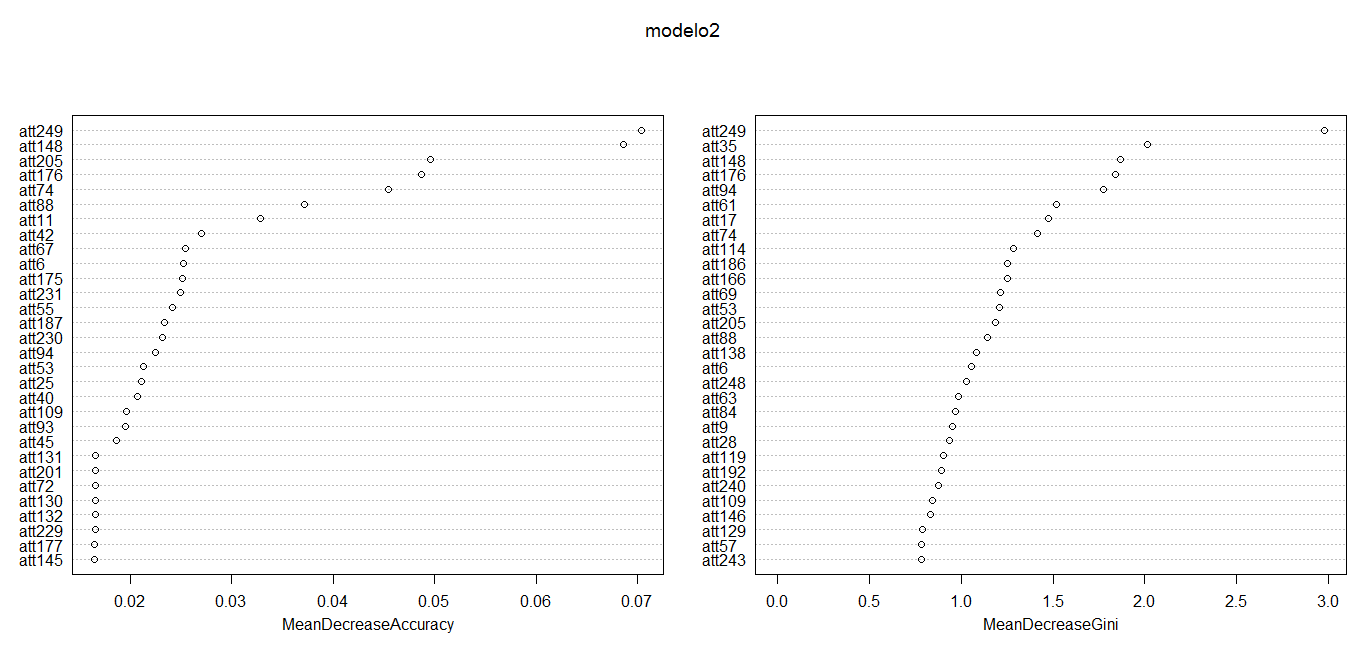
Creamos el objeto modelo1 con la función randomForest, nuestra variable dependiente es class y el resto son nuestras variables independientes. Comentamos las opciones empleadas. ntree nos permite especificar el número de árboles a realizar, importance incluye en el objeto las «medidas de importancia», maxnodes indica el número máximo de nodos en nuestros árboles y mtry indica el número máximo de variables en los modelos creados. Estas dos últimas opciones encaminadas a que los tiempos de ejecución no se alarguen, ya que es un proceso que puede alargarse. En este caso para medir la importancia de las variables empleamos la función importance sobre el modelo creado. Ordenamos ascendentemente con sort_df de la librería reshape por la medida MeanDecreaseGini. El índice de Gini es una «medida de desorden» en este caso MeanDecreaseGini tiene el siguiente sentido, a mayor medida mayor importancia en los modelos creados ya que valores próximos a 0 para el índice de Gini implican un mayor desorden y valores próximos a 1 implican un menor desorden. Si computamos una medida del «decrecimiento» del índice de Gini cuanto mayor sea esta medida más variabilidad aporta a la variable dependiente.
También podemos graficar las medidas de importancia:
varImpPlot(modelo1)
Otro paquete que podemos emplear para medir la importancia es el party, por ejemplo:
library(party)
set.seed(5)
def = cforest_classical(ntree=500, mtry=25)
modelo2 = cforest(class~., data = datos2, controls=def)
importancias = varimp(modelo2, conditional = TRUE)
Un comentario, en los modelos realizados el paquete party el tiempo de ejecución se ha alargado mucho, no me está gustando. Otro paquete disponible es el varSelRF:
#install.packages("varSelRF")
library(varSelRF)
modelo3 <- randomForest(class~.,data=datos2,
ntree=500,importance=TRUE,maxnodes=10,mtry=25)
importancia3 <- randomVarImpsRF(xdata=datos2[,-177],Class=datos2$class,
forest=modelo3,usingCluster = FALSE)
La función randomVarImpsRF nos permite determinar la importancia de las variables empleadas en los modelos. También este paquete ha implicado unos mayores tiempos de ejecución. Tres formas de obtener «bosques» y emplearlos para medir como influyen las variables cuantitativas en modelos de clasificación. Yo en mi trabajo he empleado siempre el ramdomForest con la función importance pero me gusta mostraros distintos métodos. Espero que os sirva de ayuda en vuestros análisis. Saludos.
Es muy buen criterio. Suscribo lo dicho.
A veces lo «fabrico» a mano creando muchos árboles sobre selecciones distintas de puntos y contando el número de veces que cada variable entra en uno de tales árboles.
¿A veces lo fabricas? Paquetiza compañero paquetiza.
Ese comentario parece mío, no tuyo.
Hola,
¿Sabéis cuál es la función que me mide la importancia de variables cualitativas? En realidad tengo variables cualitativas y cuantitativas, ¿miro las importancias por separado?
¡gracias de antemano y gracias por los comentarios!
Yo he realizado este proceso con variables dicotómicas de factores. Por eso hay una macro de SAS al respecto. Transforma tus factores en variables 0 y 1 y mételas en el modelo.
Hola rvaquerizo, cual es la función que comentas de SAS?
No hay una función como tal en SAs para medir la importancia de las variables. Al final es mejor llevarse los datos a R.
ok, gracias, entonces a la macro a la que te refieres es una que tu creaste?
Si, es la macro que transforma factores en variables dicotómicas, por ejemplo: Sexo {H,M} genera Sexo_H {0,1} Sexo_M {1,0}.
Estaba mirando si existía algún nodo de Enterprise Miner al respecto y no he visto nada.
Si se me ocurre algún proceso iterativo para medir la importancia de las variables de alguna forma con SAS lo colgaré.
ok, muchas gracias, una duda, estaba revisando tu documento acerca del uso del proc Logistic y me queda la duda de que es vinculación?
Interesante pregunta. La vinculación es una forma de medir la unión que tiene un cliente con una compañía. En el caso de los bancos se suele emplear el número de productos y servicios, hay otros que emplean el criterios financieros. Las aseguradoras analizan el número de pólizas que tiene un mismo cliente, las compañías de telefonía el número de línesas,… En cada organización es distinto.
sería un tipo de indice de producto cruzado, aunque se podria implementar algun score para medir la vinculación con el mismo logistic quiza
Hola! Muchas gracias por la entrada porque resulta muy interesante.
Estoy probando los random forest como método de clasificación de una variable dependiente binaria y con variables explicativas categóricas. En tu entrada dices que hay otras formas de ver la importancia de las variables cualitativas, ¿quiere decir esto que no es correcto hacerlo como propones para este tipo de variables?, ¿qué método recomiendas?.
Saludos.
Prueba a emplear randomForest SÓLO con factores, también te servirá. Pero sólo con factores. Porque desconozco que puede ocurrir si probamos con factores y variables continuas eso tendré que investigarlo, se me ocurre que una variable continua la podría tramear en 100 partes o algo así, pero no me hagas mucho caso. Saludos.
que es una frecuencia cualitativa?
Hola, podría ser la frecuencia de una distribución cualitativa. Ejemplo, cuantos hombres y mujeres. El sexo es una cualidad, no es una cantidad.
Pingback: Trucos SAS. Medir la importancia de las variables en nuestro modelo de regresión logística » Análisis y decisión
buenas tardes, necesariamente la función Importante (para medir la importancia de las variables ) es solo para variables cuantitativas, es que acabo de realizar un modelo con todas las variables y me resulta valores de MeanDecreaseGini demasiados grandes, mayores a 1, estará bien los resultados?,Gracias
Como puedo interpretar las salidas de R al ejecutar la funcion randomForest?
Hola Laura, el objetivo es determinar que variables tienen mayor importancia dentro del modelo. Una vez selecciones tú modelo realizas el árbol y ya puedes interpretarlo.
Cuando obtengo las importancias incMSE, bajo que criterio puedo decir que una variable es mas importante que la otra
Aquí lo explican de modo muy completo:
http://stackoverflow.com/questions/27918320/what-does-negative-incmse-in-randomforest-package-mean
Saludos.
Hola rvaquerizo, muy buen post.
Ayudame con algo porfa.
tengo un set de datos con variables cualitativas y cuantivas.
este set tiene datos de calificaciones de alumnos, y varibales como sexo, edad, nivel academico,etc . Debo determinar cual o cuales variables influyen mas en las bajas calficaciones. Que me aconsejas??, teniendo en cuenta que son variables cualitativas y cuantitativas.
Gracias
Que sean todas cualitativas, si tienes variables numéricas hazlas tramos y así tendrás variables cualitativas y podrás emplear árboles o GLM. Saludos.
una consulta si randomforest como dices al comienzo que son multiples arboles de decision, y este ultimo trabaja las variables cualitativas convirtiendolas a variables dummy . ese mismo procedimiento tambien se podria aplicar en el modelo de randomforest, solo creando variables dummy. estoy en lo correcto? . gracias de antemano señor rvaquerizo y saludos
Hola,
Quería saber cuál es la interpretación de las cvi, de la importancia. Son valores de 0 a 1? Existe algún criterio para saber si a partir de cierto número es un buen predictor en el modelo. Trabajo con puntuaciones en subtipos de maltrato para predecir trastorno bipolar y el subtipo con el mayor cvi es de 0.046. Se le podría considerar importante?
Gracias