Capítulo 5 Representación gráfica básica con ggplot
Además del manejo de datos es necesario tener conocimientos de representación de datos. En este trabajo se va a emplear la librería de R ggplot y se trabajarán las representaciones gráficas básicas que ha de manejar un científico de datos. Se pueden explorar las múltiples posibilidades que ofrece esta librería en la web Statistical tools for high-throughput data analysis que dispone de un gran número de recursos para R entre los que destaca el uso del paquete ggplot.
Iniciamos el proceso cargando la librería tidyverse donde podemos encontrar ggplot como podemos en los mensajes que nos ofrece cuando la cargamos.
Ya está disponible esta librería gráfica, se puede observar en el mensaje Attaching packages. A modo introductorio, cuando se emplea ggplot siempre se requiere:
dataconjunto de datos que tiene la información a representar, siempre será un data frame.aesAesthetics es la parte del código donde pondremos lo que deseamos visualizar por ejes además de otras características como color, grupos,…geom_Geometry define el tipo de visualización que deseamos, también podremos establecer las variables a visualizar y otras opciones de visualización.
La representación gráfica dependerá del tipo de variable que deseamos estudiar, recordando capítulos anteriores que hay dos grandes dos tipos, variables cuantitativas y variables cualitativas que, en la dialéctica de R, se denominan factores .
Para estudiar variables cuantitativas emplearemos:
- Histogramas
- Gráficos de densidad
- Boxplot
En variables cualitativas:
- Gráficas de tarta
- Gráficos de barra
También podremos realizar visualizaciones que contengan dos variables, en ese caso se combinan tipos de variables.
- Gráficos de líneas
- Gráficos de puntos
5.1 Histogramas
Es una representación gráfica para variables numéricas en forma de barras donde el alto de la barra representa la frecuencia de los valores numéricos agrupados. Nos permite visualizar la forma y la distribución de una variable numérica.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.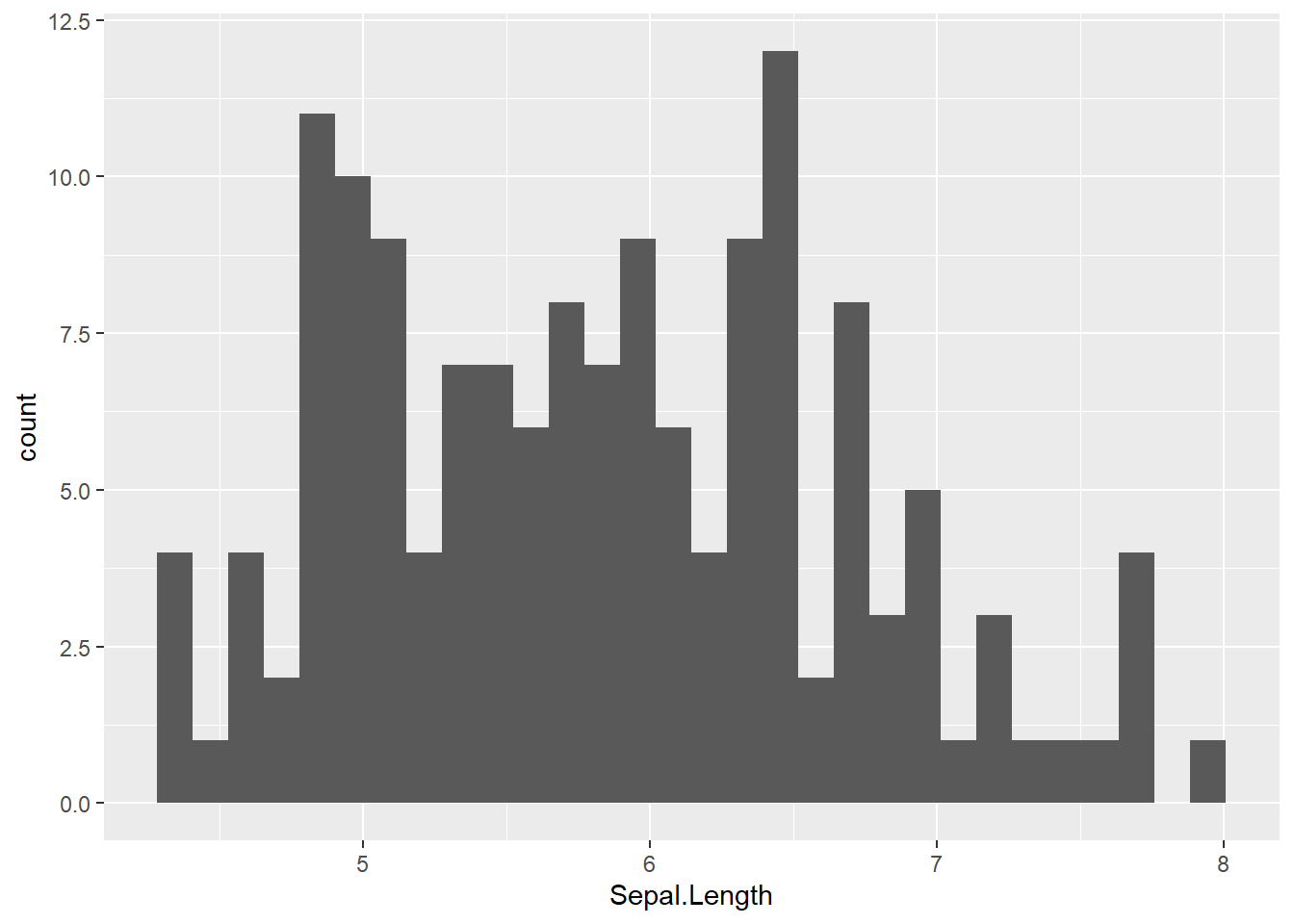
Se observa la sintaxis más básica como ggplot(data = data.frame , aes(x=var.cuantitativa)) + geom_histogram() que siempre se empleará con ggplot() y si se añaden opciones al gráfico lo haremos con +. En este caso, solo se representa una variable que estará en el eje x de menor a mayor valor y unas barras que en función de su anchura representan un tramo que divide la variable cuantitativa en tramos de igual tamaño y la altura de las barras recoge el número de observaciones que tiene cada tramo.
Se puede establecer el número de tramos que por defecto está establecido en 30 como nos dice el comentario que ofrece R tras ejecutar el código. Para ello se juega con la opción bins=
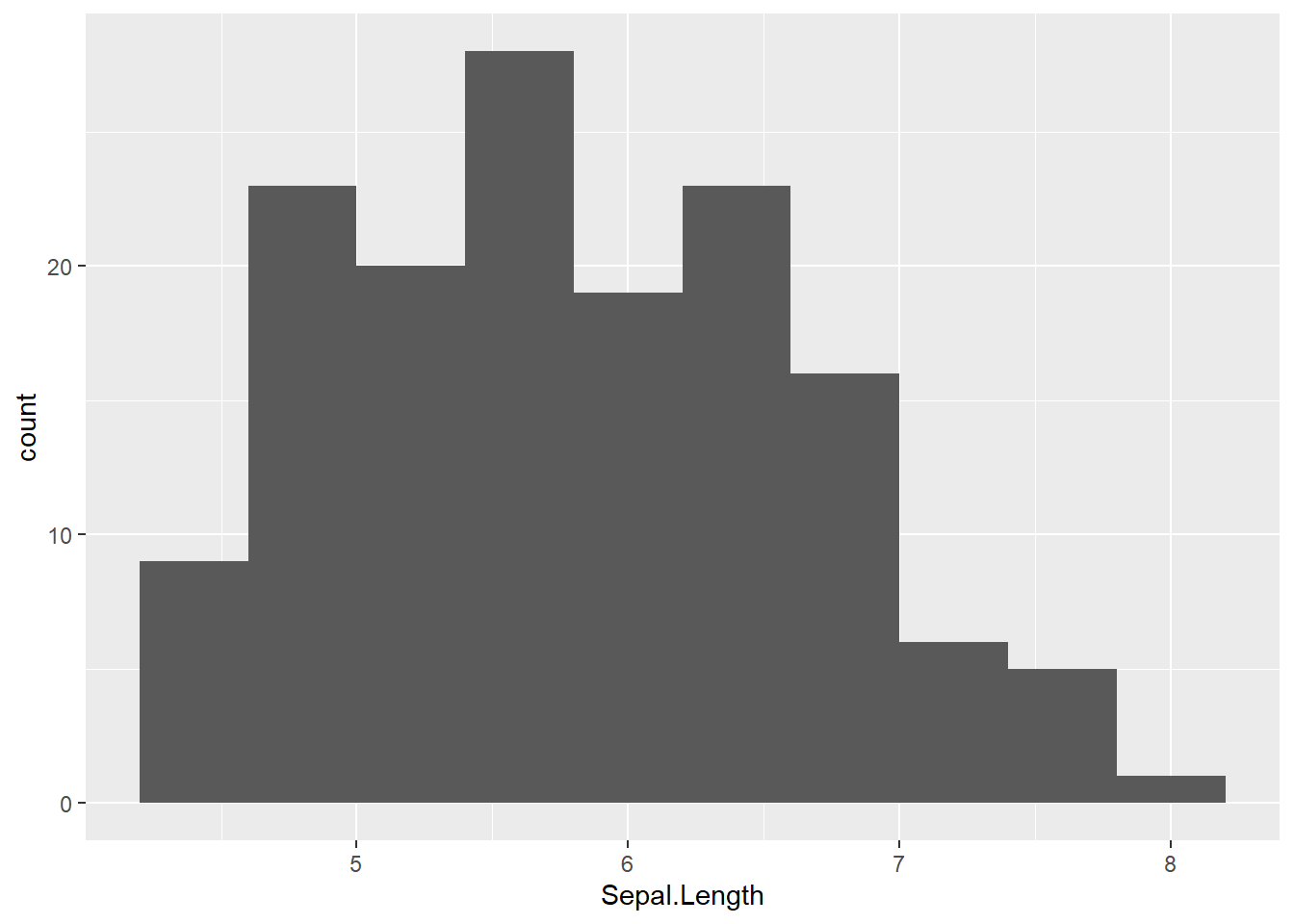
Esa anchura del tramo puede hacer que la variable tome una u otra forma, por ese motivo es recomendable ver ese histograma como una función continua, como un gráfico de densidad.
5.2 Gráficos de densidad
Es una variación del histograma que permite ver la distribución de una variable mediante una línea continua.
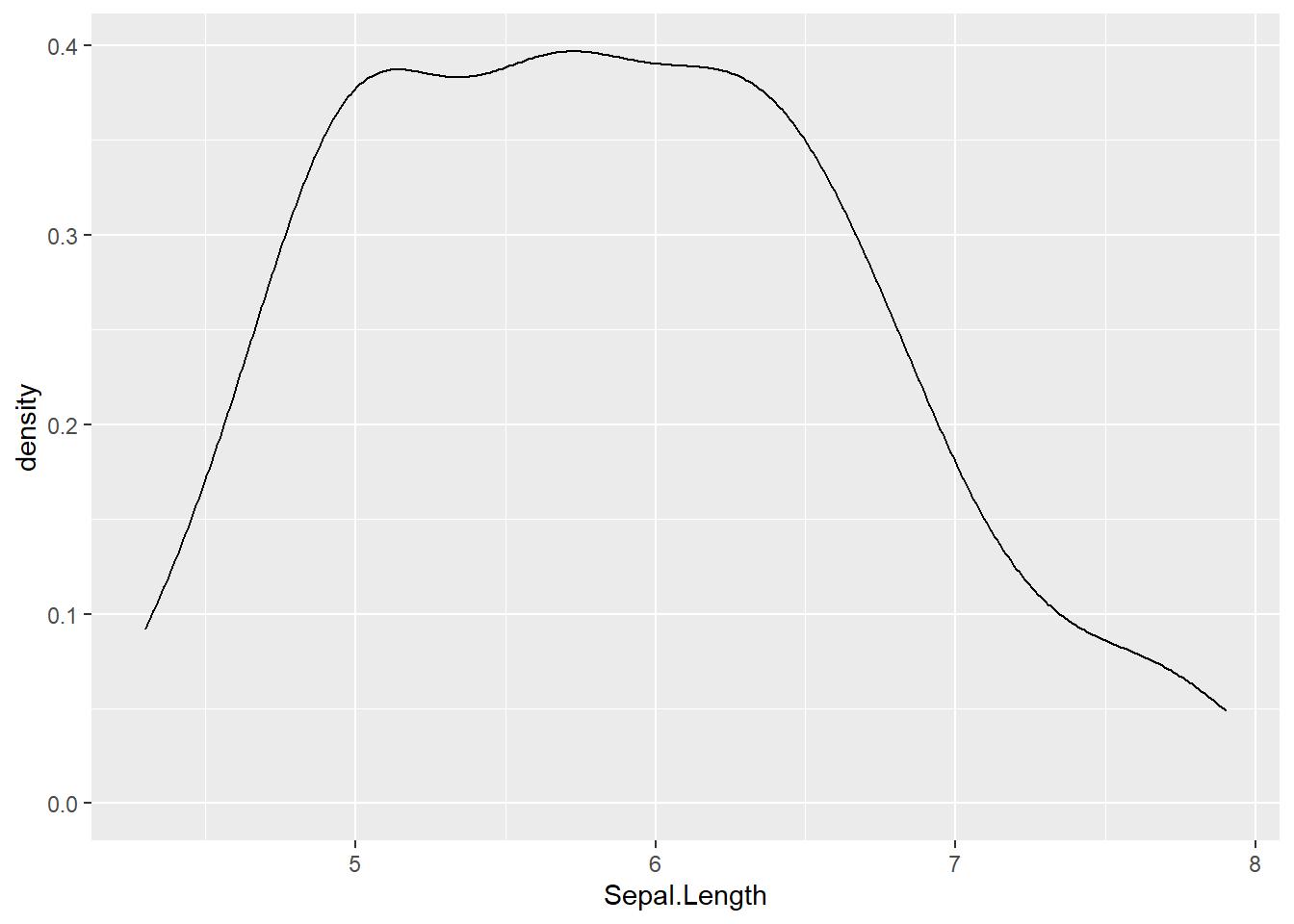
Ver la distribución de ese modo limita el problema que supone la anchura de las barras del histograma. Este gráfico representa lo mismo que el histograma pero se distribuye de una forma continua. En el eje x se representa el % de observaciones de forma que el la función que representa el gráfico de densidad deja el 100% de los datos bajo ella. El valor de lo que queda debajo de la función es 1.
5.3 Gráficos de caja (boxplot)
Gráfico que recoge información relevante sobre la distribución, las medidas de dispersión y centralidad de una variable numérica.
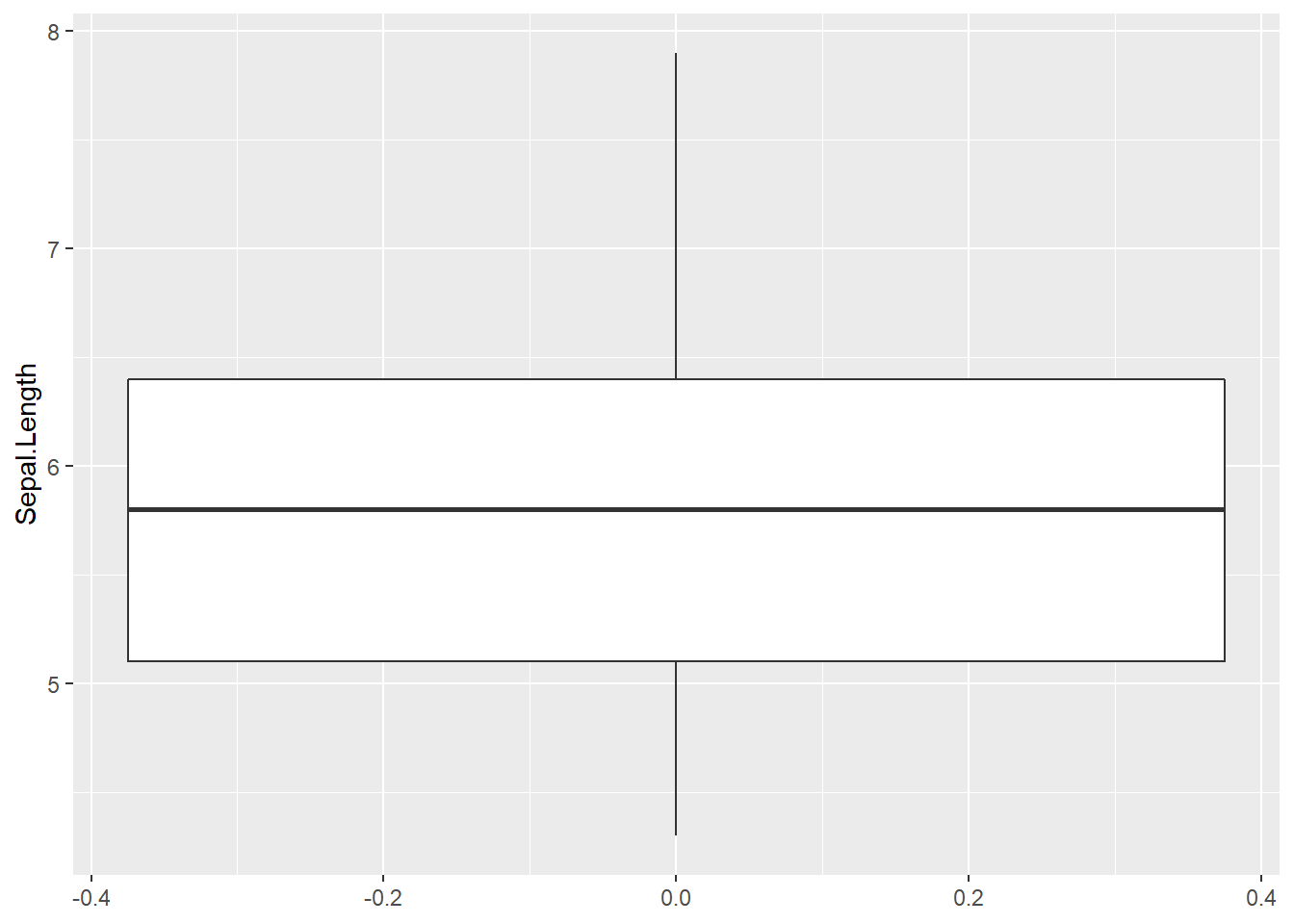
Este análisis permite recoger mucha información sobre la que volveremos posteriormente. Es habitual categorizar este tipo de gráficos para estudiar visualmente diferencias en la distribución:
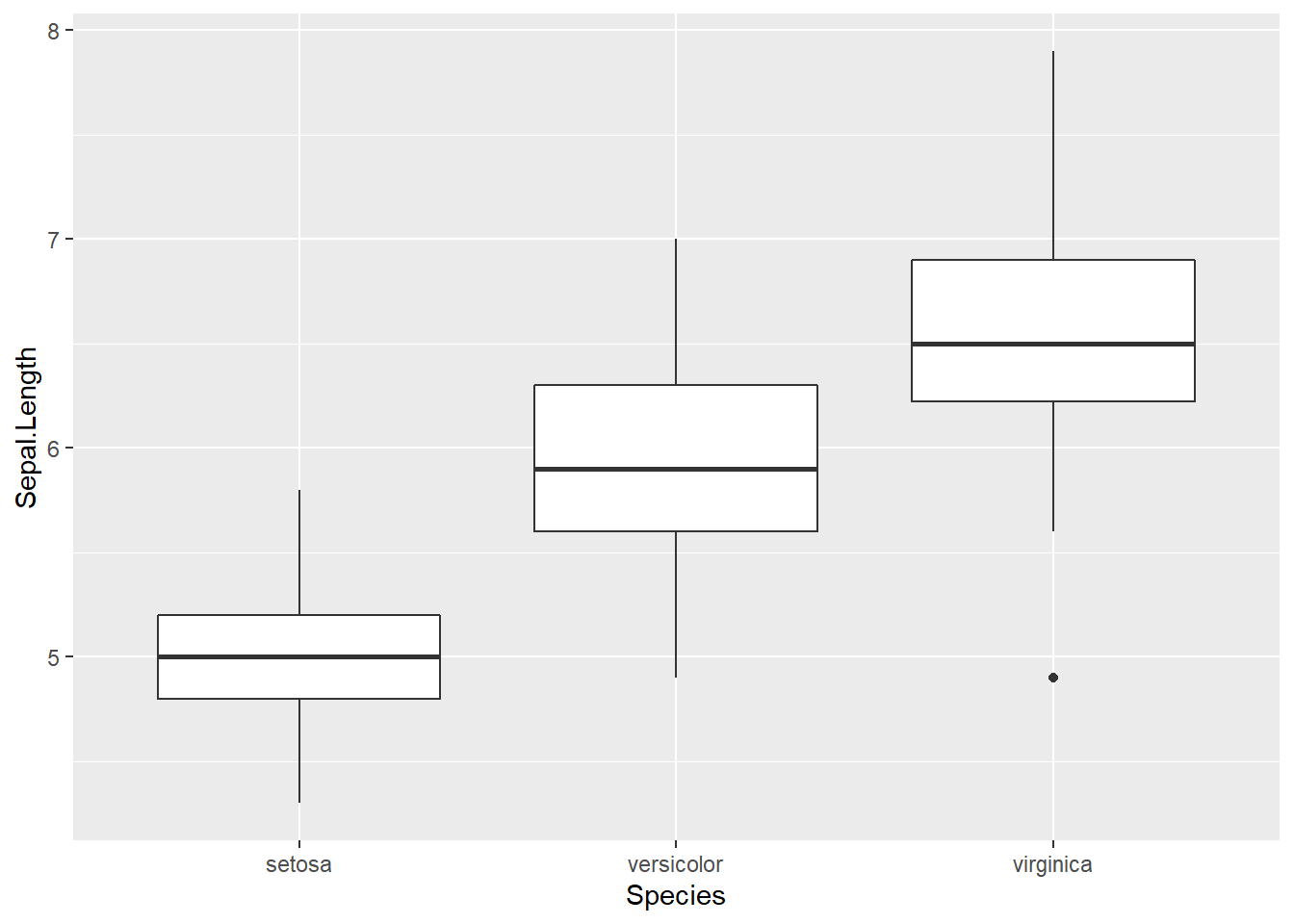
En este caso, al representar dos variables en aes se especifican tanto la x como la y que crea grupos, en realidad este gráfico no deja de ser la combinación de dos variables.
5.4 Gráficos de tarta
Gráficos empleados para mostrar proporciones en variables categóricas, el circulo representa el total, el 100% y cada porción una parte de ese 100%.
resumen <- iris %>% group_by(Species) %>% summarise(conteo=n())
ggplot(resumen, aes(x='', y=conteo, fill=Species)) + geom_bar(stat="identity", width=1) +
coord_polar("y", start=0)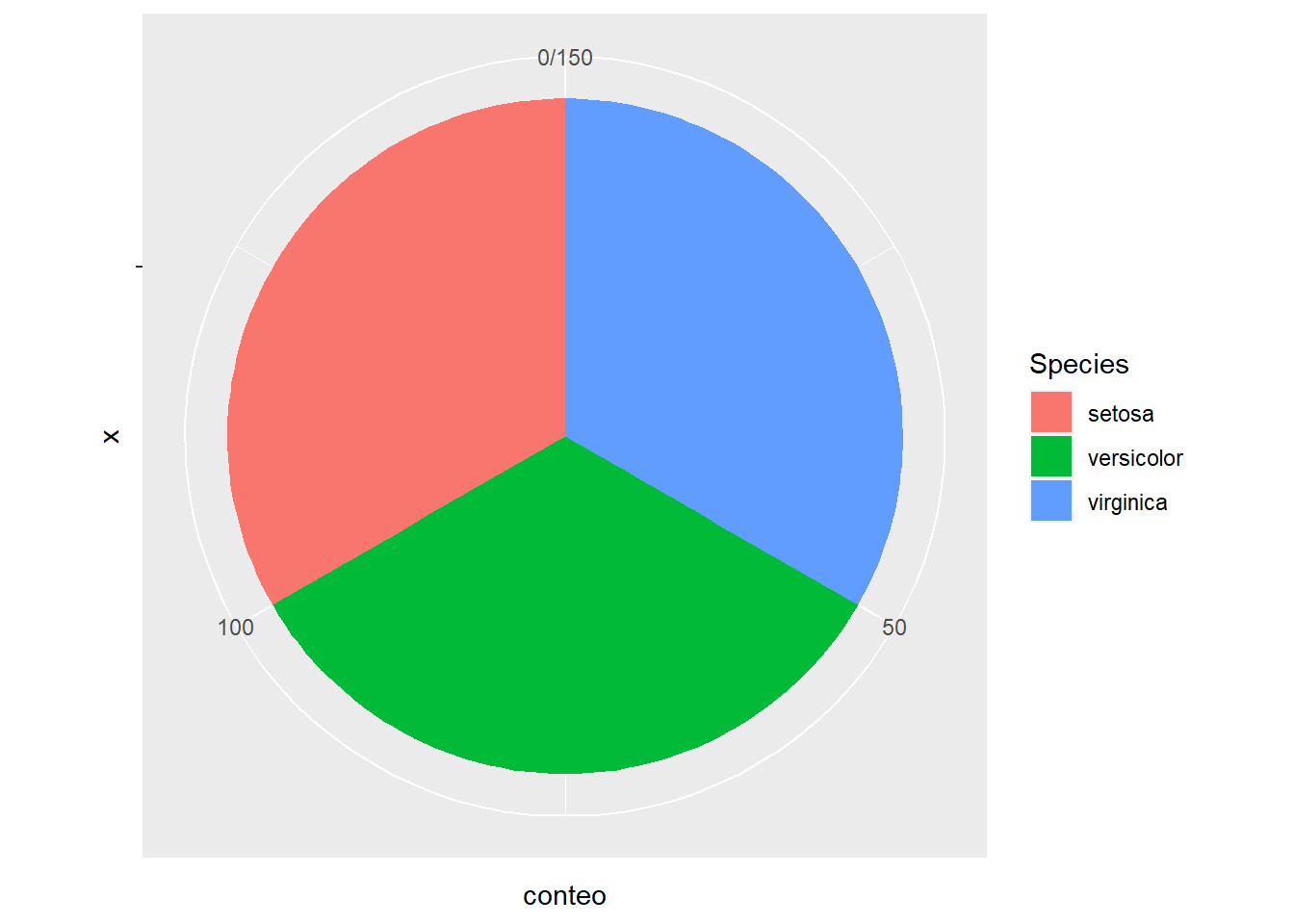
Una práctica recomendable a la hora de realizar gráficos con factores y ggplot, la creación de un data frame previo con la agrupación por el factor en análisis y el cálculo de la variable a representar, en este caso se desea ver la proporción de cada especie en los datos. No hay variable x, la medida es esa sumarización que se ha llamado conteo y cada grupo será una especie. Es un factor, cuando representemos factores en el 80% de las ocasiones aparecerá geom_bar y si ya hemos creado la variable a representar, como es el caso porque hemos hecho una sumarización previa entonces se usará stat = 'identity'. Para especificar que sea un gráfico de tarta añadiremos coord_polar
5.5 Gráficos de barras
Gráfico empleado para representar frecuencias de variables categóricas (factores) en un eje se pondrá el factor y en el otro la frecuencia total o frecuencia relativa del factor
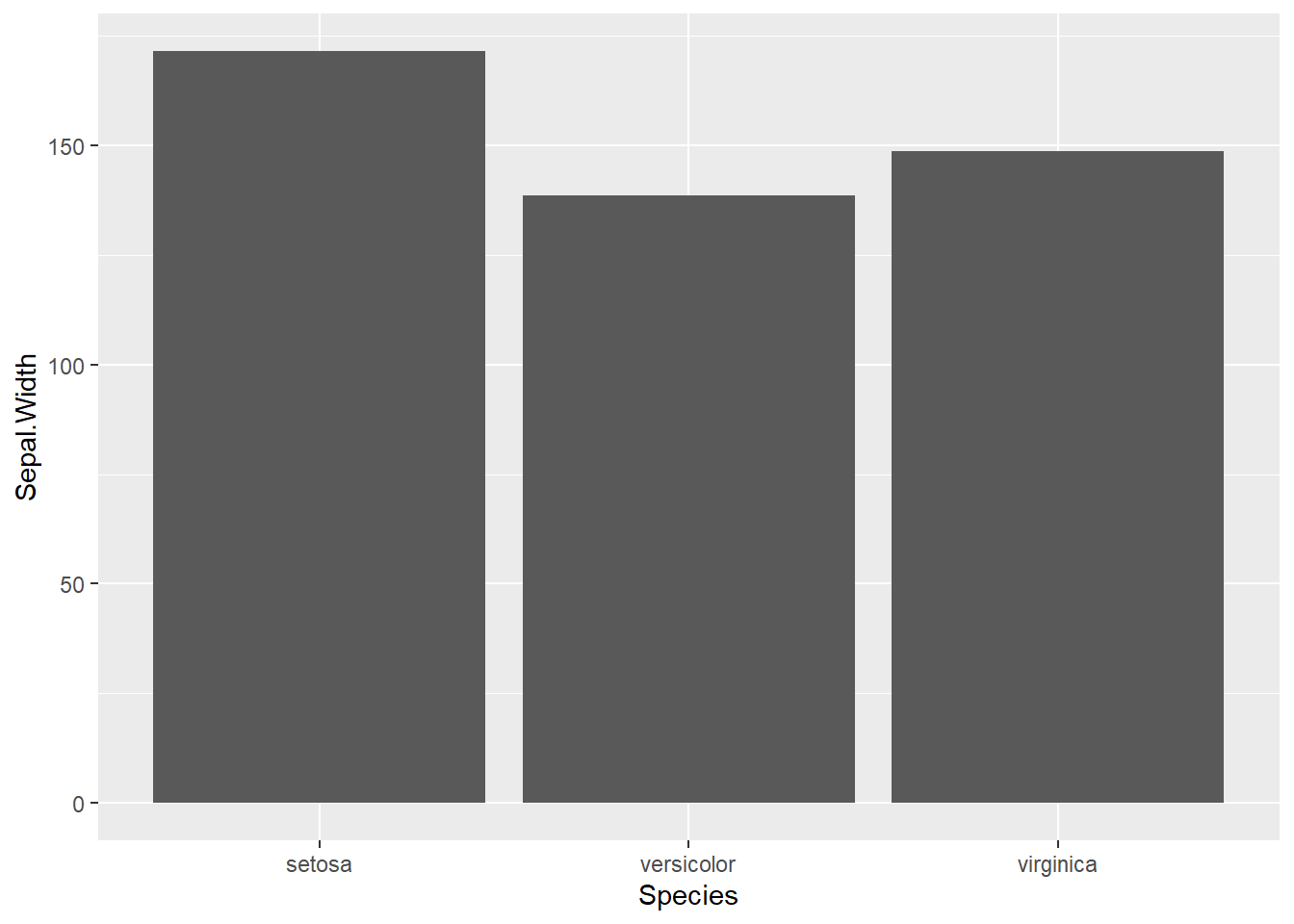
También es habitual la combinación de 2 factores en este tipo de gráfico. Creamos un nuevo factor como resultado de la comparación de la longitud del sépalo.
iris <- iris %>% mutate(Sepal.Length.factor = case_when(
Sepal.Length>=5 ~ 'Mayor 5 mm',
TRUE ~ 'Menor de 5 mm'))Se emplea la función case_when para crear ese factor, cada condición tiene un valor y por último con TRUE tenemos los restantes registros. Vamos a representar 3 barras, una por especie, y dentro de cada una de ellas vemos el número de registros separada por ese factor que se ha creado con anterioridad.
## `summarise()` has grouped output by 'Species'. You can override using the `.groups` argument.ggplot(resumen, aes(x=Species, y=registros, fill=Sepal.Length.factor, color=Sepal.Length.factor)) + geom_bar(stat="identity")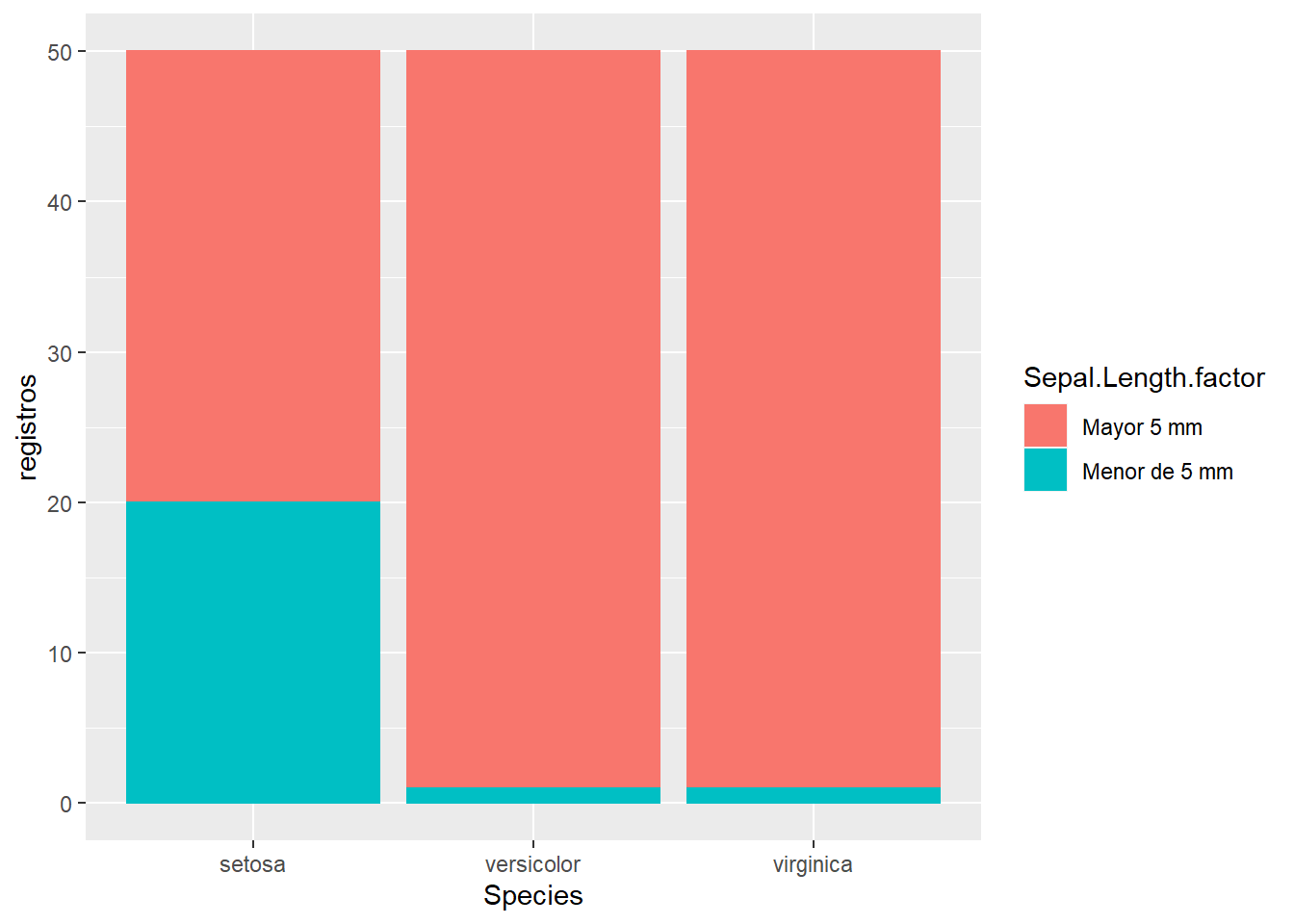
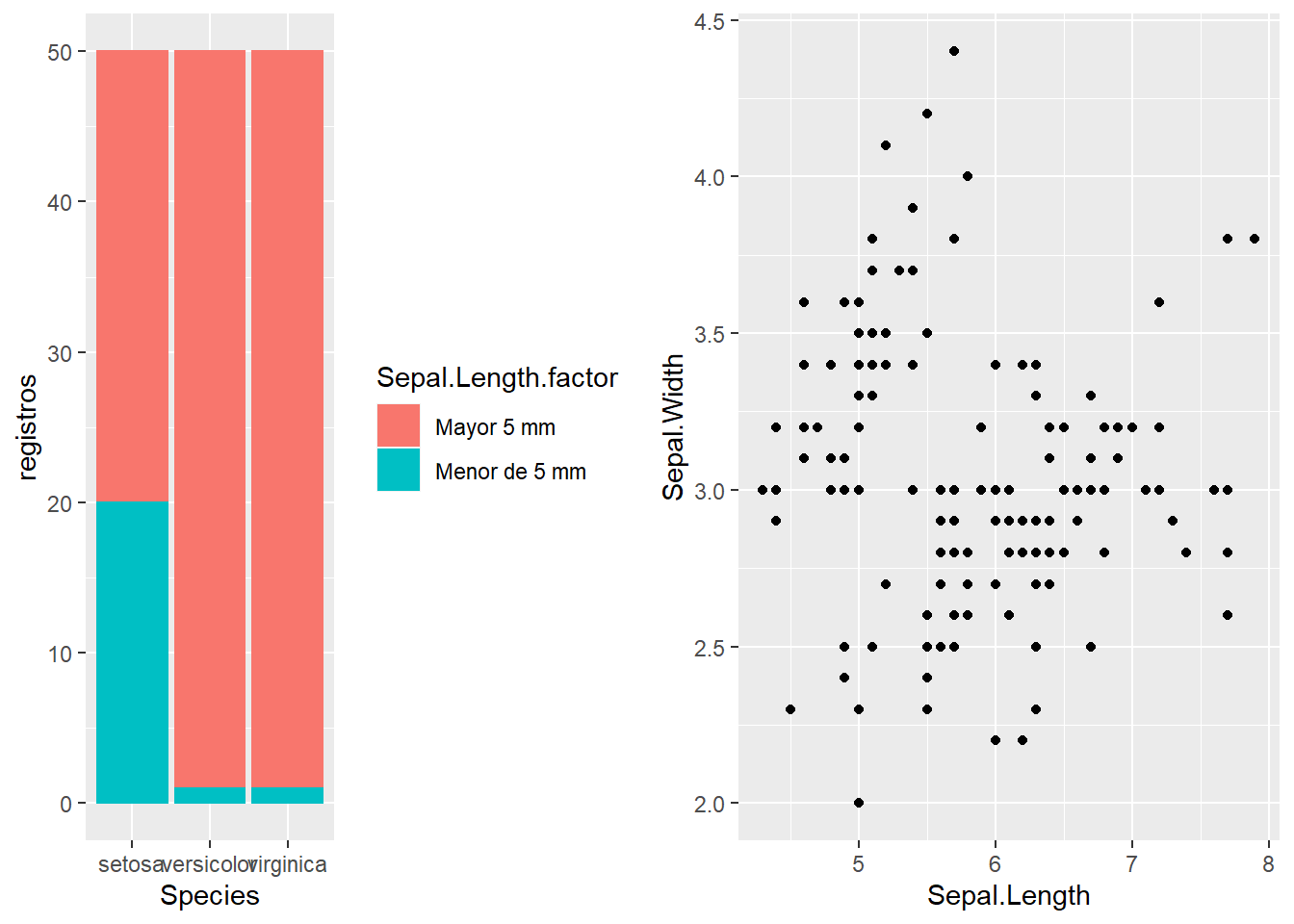
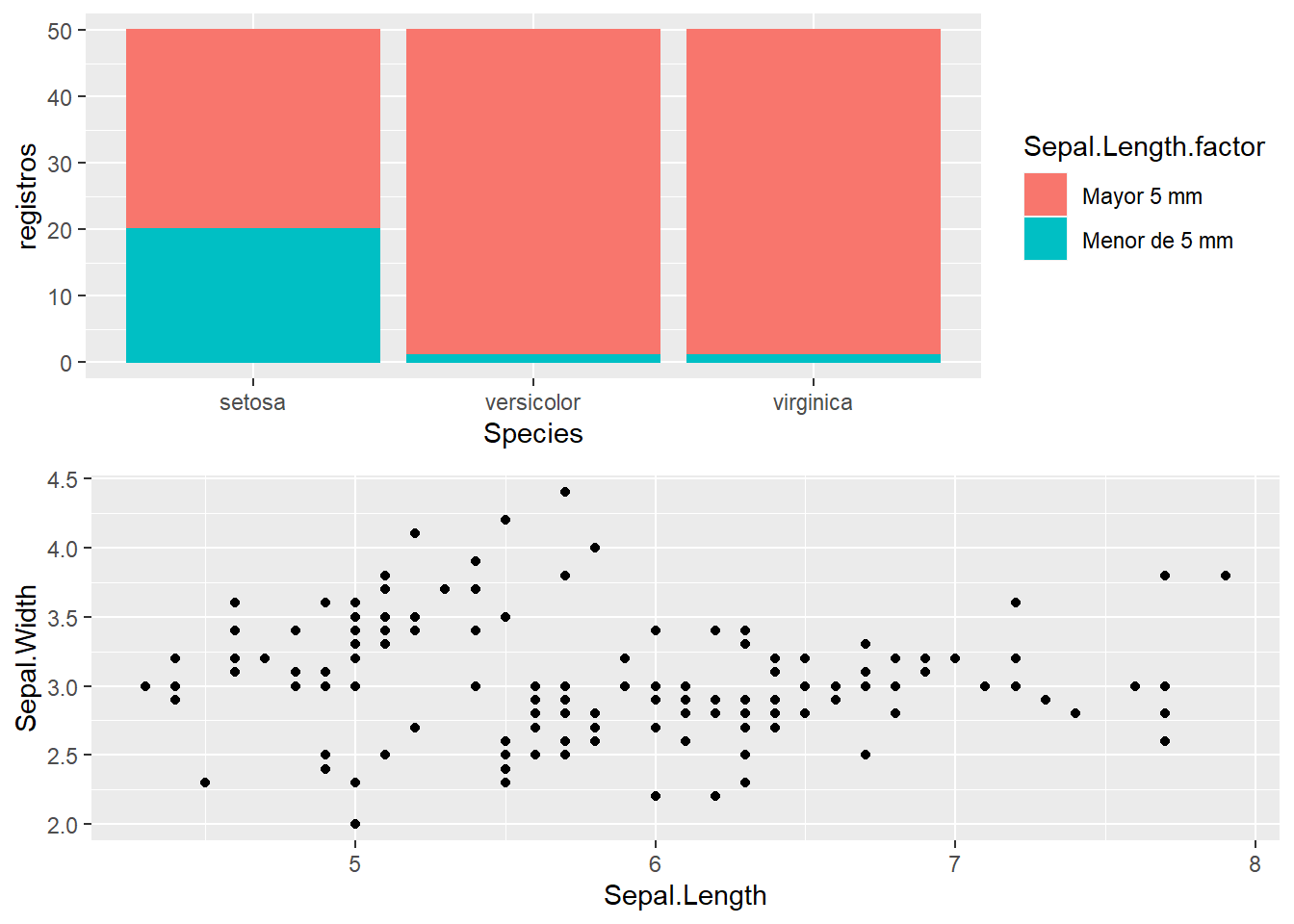
Se puede ver como este gráfico de barras distingue el número de registros por especie y de forma apilada, uno encima de otro, tenemos distintos colores en las barras que nos identifican aquellos registros que tienen la longitud del sépalo mayor de 5 mm. Este tipo de gráfica de barras son barras apiladas. Además de crear barras apiladas se pueden crear barras agrupadas:
ggplot(resumen, aes(x=Species, y=registros, fill=Sepal.Length.factor, color=Sepal.Length.factor)) +
geom_bar(stat="identity", position = "dodge")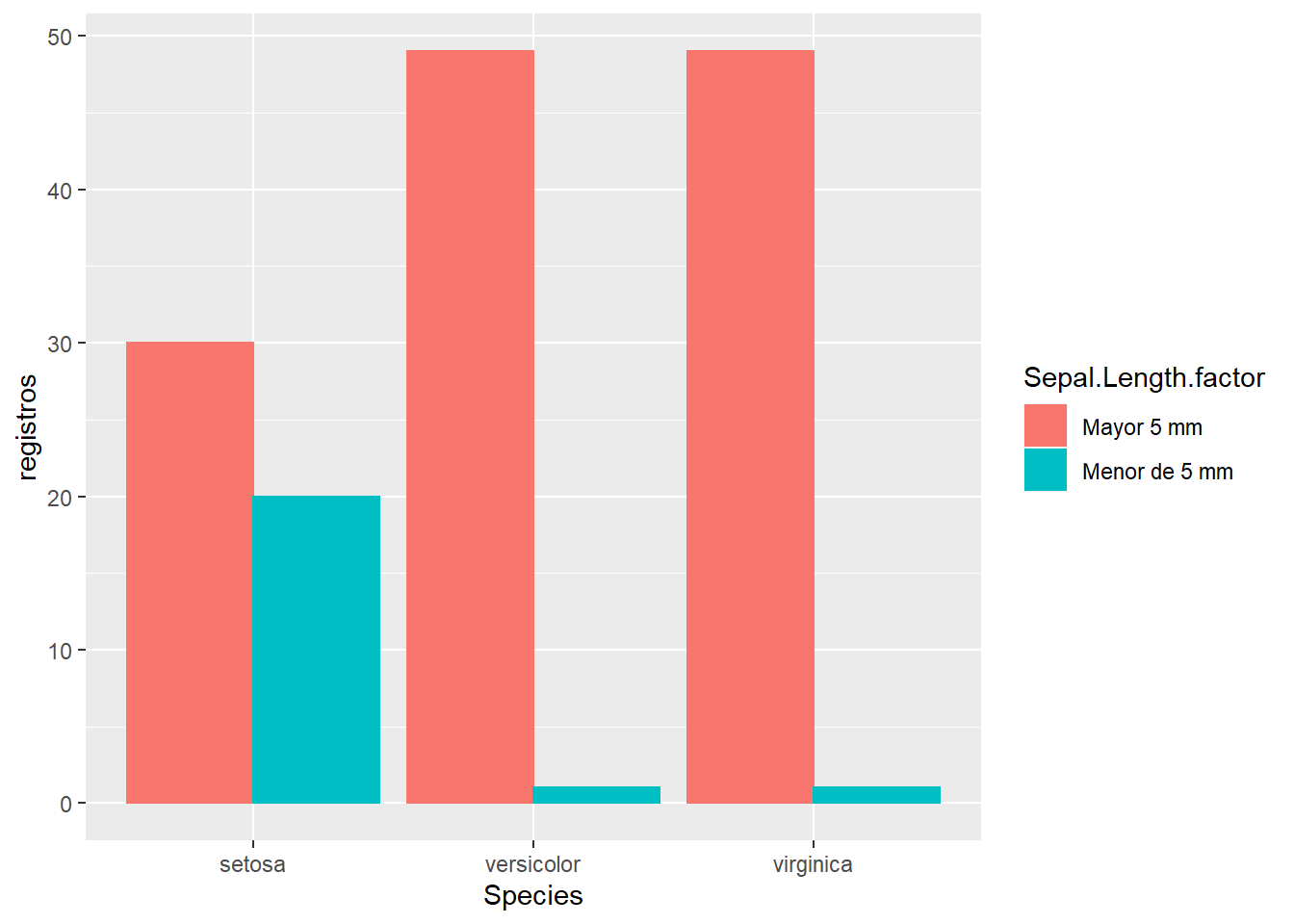
Para modificar el tipo de gráfico sólo tenemos que emplear la opción position = "dodge".
5.6 Gráficos de líneas
Esta representación gráfica muestra dos variables como una secuencia de datos unidos por una línea, muy habitual en las series temporales. En los datos utilizados no se dispone de datos temporales pero se puede emplear para sumarizar la media de la anchura del sépalo por especie.
resumen <- iris %>% group_by(Species) %>% summarise(media=mean(Sepal.Width))
ggplot(resumen, aes(x=Species, y=media, group=1)) + geom_line()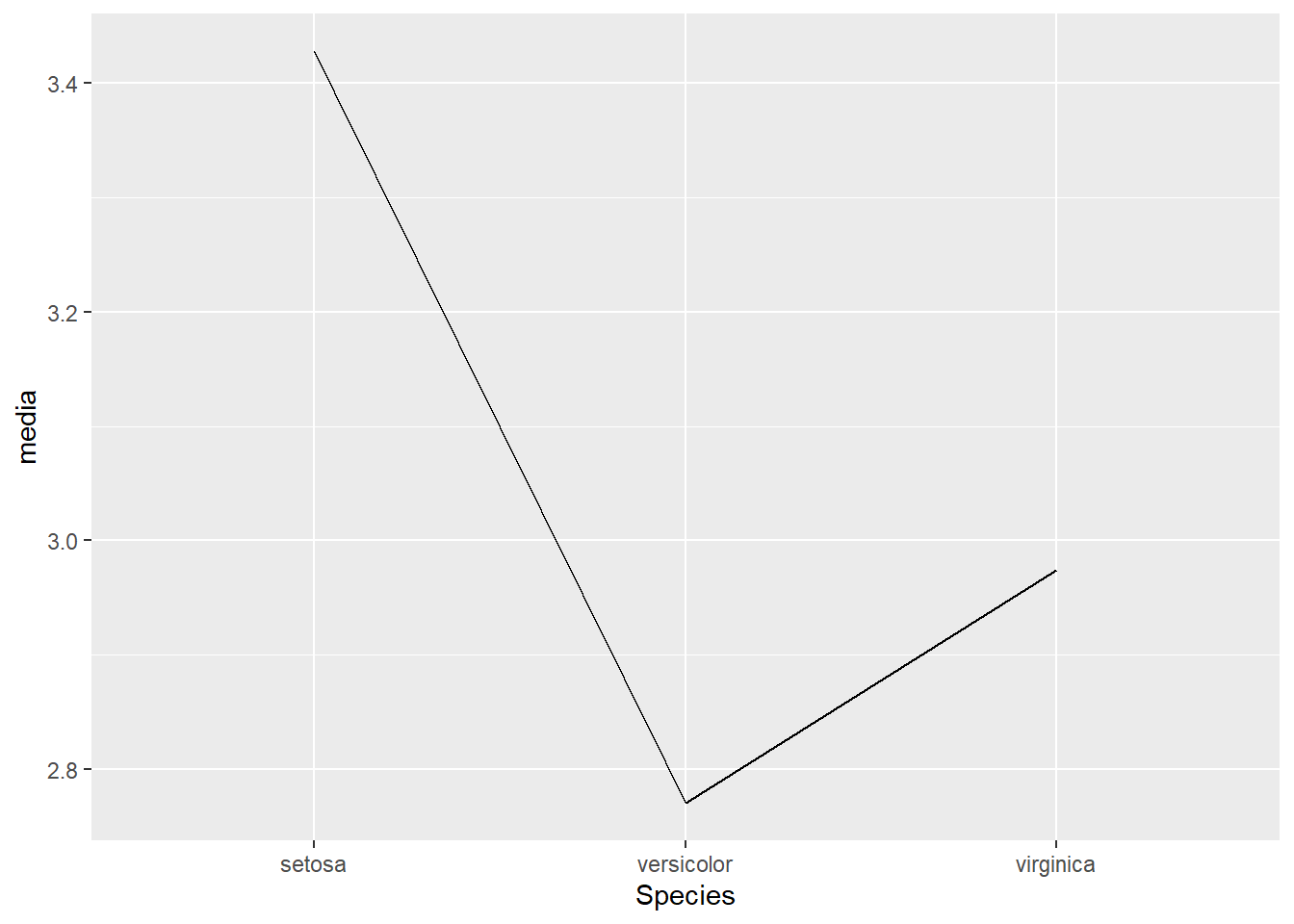
El eje x es la especie y en el eje y tenemos la media de la anchura del sépalo, como en casos anteriores se sugiere realizar la sumarización previa creando un conjunto de datos de resumen. Destacar la necesidad de poner la opción group = 1 ya que es necesario especificar el “número de cortes”, de este modo especificamos que el 100 de las observaciones están en un grupo.
5.7 Gráfico de dispersión
Gráfico empleado para visualizar en 2 ejes variables numéricas, muy útil para estudiar relaciones entre variables.
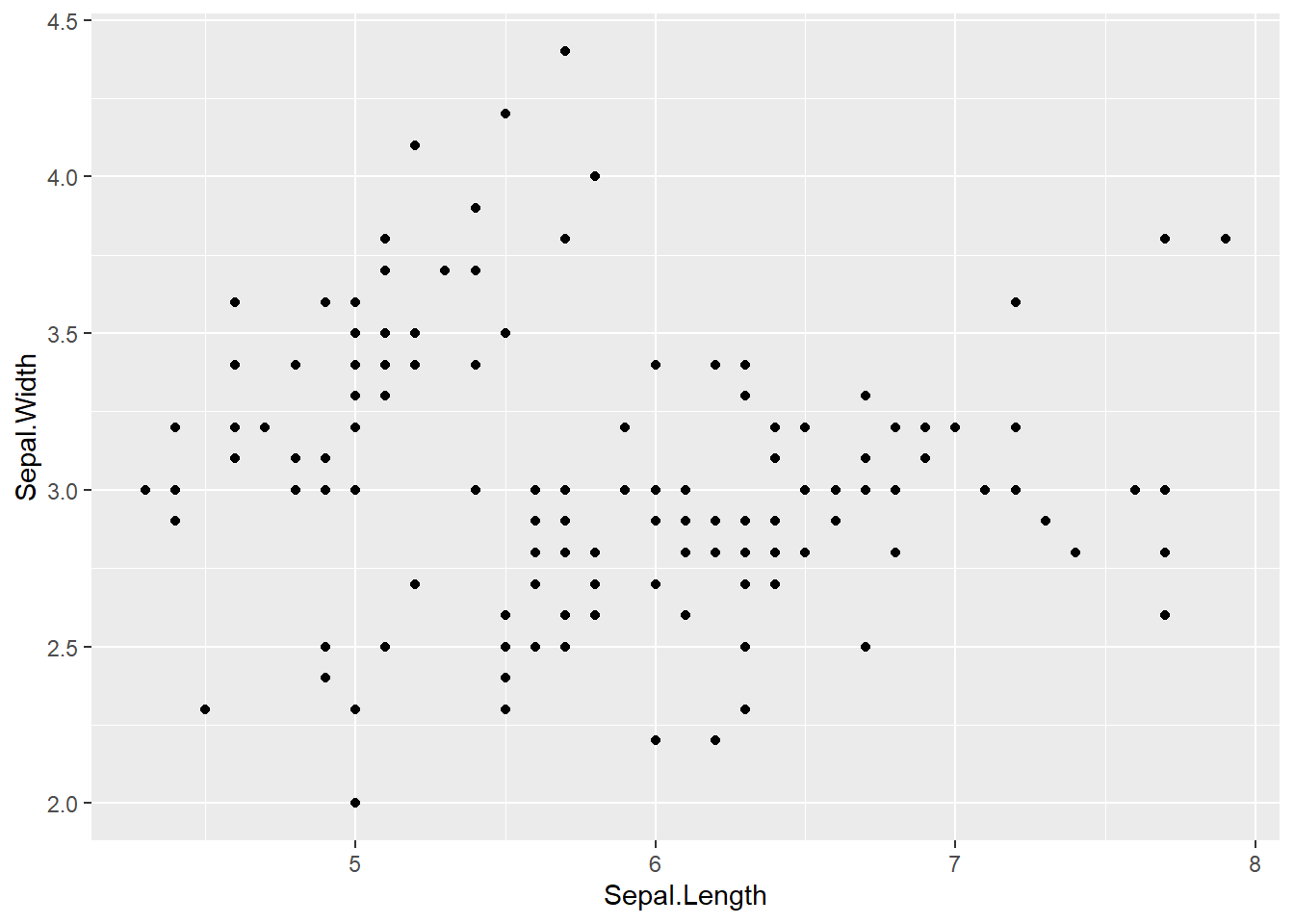
Un gráfico sobre el que se volverá de forma reiterada a lo largo del ensayo cuando se trabaje la regresión lineal.
5.8 Múltiples gráficos con gridExtra
Para incluir múltiples gráficos con ggplot se dispone de la librería gridExtra, la sintaxis es sencilla ya que sólo es necesario crear un objeto con el gráfico ggplot y emplear la función grid.arrange para representar esos objetos.
library(gridExtra)
resumen <- iris %>% group_by(Species, Sepal.Length.factor) %>%
summarise(registros = n())
p1 = ggplot(resumen, aes(x=Species, y=registros, fill=Sepal.Length.factor, color=Sepal.Length.factor)) + geom_bar(stat="identity")
p2 = ggplot(iris, aes(x=Sepal.Length, y=Sepal.Width)) + geom_point()
grid.arrange(p1, p2, nrow=1)