En el blog del profesor Serrano tomé contacto con el paquete RGoogleTrends para leer datosde Google Trends. Tras diversos intentos y analizando bien el paquete RGoogleTrends no he sido capaz de hacerlo funcionar. Sin embargo sólo hay que leer un csv, por esto podemos emplear read.csv para descargarnos los datos de Google Trends y analizarlos con R. Además el objeto resultante nos será mucho más familiar que el generado por RGoogleTrends. Para realizar esta lectura necesitamos lo siguiente:
- Una cuenta de Google y permanecer conectado a ellas (tema de cookies)
- Tener explorer como navegador predeterminado (¡?, más tema de cookies)
- Poder conectar R con internet, en vuestro puesto de trabajo a lo mejor necesitáis recordar esta entrada
Pues con estas condiciones ya podemos descargar datos de Google Trends. En este ejemplo vamos a analizar las búsquedas de los términos «SAS software» y r-project:
datos1=read.csv("http://www.google.com/trends/viz?q=r-project&graph=all_csv&sa=N")
datos2=read.csv("http://www.google.es/trends/viz?q=sas+software&graph=all_csv&sa=N")
#Creamos data frames con los objetos descargados
datos1=data.frame(datos1);names(datos1)=c("v1","v2")
datos2=data.frame(datos2);names(datos2)=c("v1","v2")
Ya tenemos nuestros objetos en R. Vemos que los términos de búsqueda aparecen en el parámetro q. En este caso no hemos especificado la escala, pero descargamos datos relativos (CSV with relative scaling) así podremos comparar los resultados, esto tiene su importancia. Ahora hemos de trabajar con los objetos creados:
#Trabajo con datos1
modifica1=data.frame(row.names(datos1))
modifica1 = cbind(modifica1,datos1v1)
names(modifica1)=c("semana","rproject")
#Realizamos una consulta con sqldf
library(sqldf)
modifica1 = sqldf(
"select * from modifica1
where semana like '%2009%' or semana like '%2010%'
or semana like '%2011%';")
modifica1rproject=as.numeric(as.character(modifica1$rproject))
head(modifica1)
Algunos aspectos interesantes. Trabajamos con la primera consulta, replicaremos el paso con la segunda consulta. Pasamos los nombres de las filas como una variable con ello creamos un data.frame con dos variables semana y relatividad. Sólo analizamos los datos de 2009, 2010 y 2011 y empleamos la librería sqldf con el operador like. Es lo que tenemos los tipos mediocres, si a los 2 minutos no te funciona el subset tiramos de SQL y listo. Mediocre con recursos es menos mediocre. Por último transformamos un factor a número con as.character combinado con as.numeric (a lo mejor se puede hacer de una forma más elegante). Lo mismo con la segunda consulta:
#Trabajo con datos2
modifica2=data.frame(row.names(datos2))
modifica2 = cbind(modifica2,datos2v1)
names(modifica2)=c("semana","sas")
#Realizamos una consulta con sqldf
modifica2 = sqldf(
"select * from modifica2
where semana like '%2009%' or semana like '%2010%'
or semana like '%2011%';")
modifica2sas=as.numeric(as.character(modifica2$sas))
head(modifica2)
Ejecutad el código y comprobaréis que disponemos de 2 objetos con las búsquedas realizadas en Google para los términos SAS Software y R-project. Ahora los unimos y preparamos las variables fecha:
union=merge(modifica1,modifica2,by="semana")
#Pasamos el campo semana como fecha para ordenar
Sys.setlocale("LC_TIME", "English")
comparasemana = as.Date(tolower(comparasemana),"%b %d %Y")
#Realizamos una ordenación
library(reshape)
compara = sort_df(compara,vars='semana')
Mediante merge unimos los dos objetos con las búsquedas realizadas por semana de los términos R Project y SAS Software. Hemos unido mediante el campo semana que es un texto así que hemos de pasar este texto a fecha. Esta tarea la realizamos con R con la función as.Date y leemos un formato en lengua inglesa (por ello necesitamos Sys.setlocale) del tipo %b %d %Y, importante el espacio… 10 pruebas me ha costado darme cuenta del problema del espacio. Con este proceso pasamos de apr 10 2010 a 2010-04-10 y podemos realizar una ordenación para graficar la serie temporal:
win.graph()
plot(compararproject,type="l",lwd=2,
xaxs="r", yaxs = "r", xaxt="n", yaxt="n",
ylab="%",col=14,xlab="",panel.first = grid(lwd=1),
main="Búsquedas en Google R-Project vs. SAS")
points(comparasas,type="l",col=12,lwd=2)
#Ponemos los ejes
axis(1,1:nrow(compara),compara$semana,padj=0)
axis(2)
#Añadimos texto para identificar las líneas
text(40,2,"Búsquedas R Project",col=14,cex=1.2)
text(70,0.3,"Búsquedas SAS Software",col=12,cex=1.2)
No empleo ggplot2 porque se me ha olvidado su sintaxis ya que algún compañero y amigo de la blogosfera no realiza un manual sobre su uso. Y el resultado de nuestro trabajo queda:
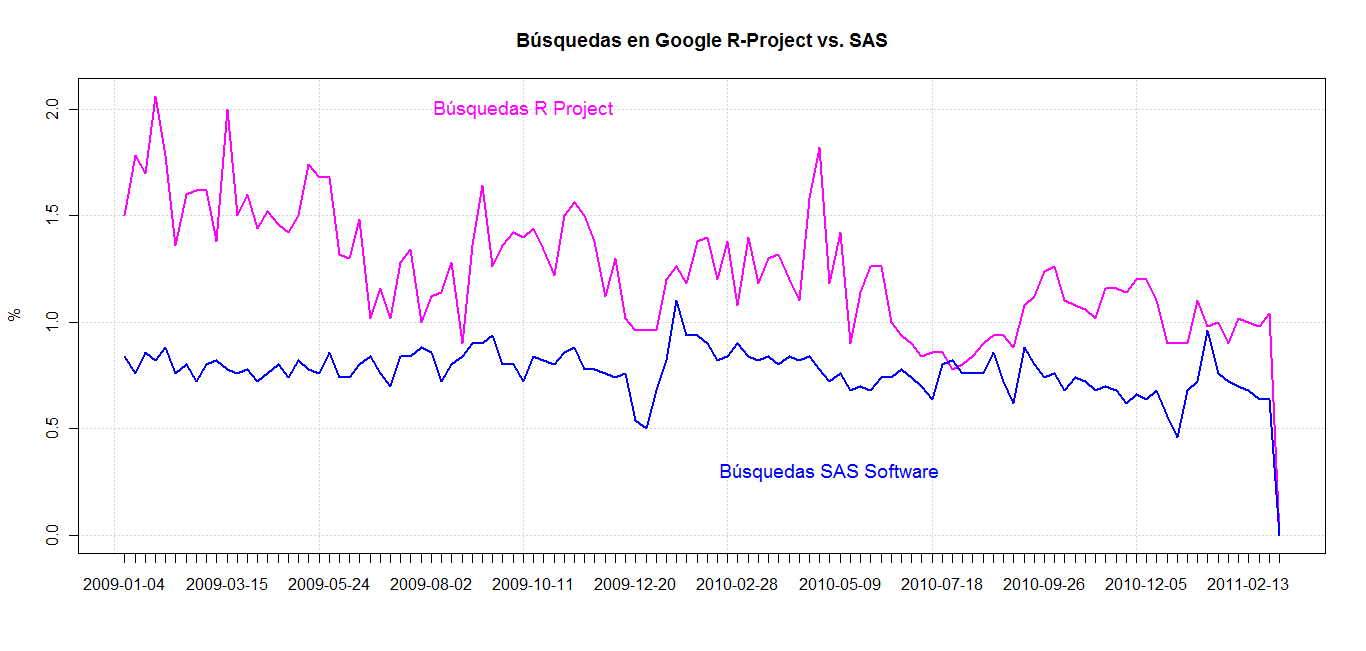
Creo que es un buen ejemplo de tratamiento de datos con R. Además de otro método de acceso a Google Trends con R. Espero que os sea de utilidad. Por cierto, ejecutadlo en vuestra consola de R y reportadme los posibles errores para seguir conociendo el acceso a Google con R. Saludos.
En la siguiente sentencia:
comparasemana =
as.Date(tolower(comparasemana),»%b %d %Y»)
que es compara?
Tengo problemas ejecutando tu código. Me dice siempre esto:
Error in file(file, «rt») : cannot open the connection
In addition: Warning message:
In file(file, «rt») :
cannot open: HTTP status was ‘203 Non-Authoritative Information’
Seguro que estoy haciendo algo mal pero no sé el qué. Creo que he hecho los 3 primeros pasos aunque no tengo muy claro qué significa permanecer conectado a la cuenta de Google. Me puedes ayudar?
Gracias :)
Hola, yo no tengo ese problema. Pero han debido de cambiar la API. Voy a rehacer la entrada empleando estas funciones https://github.com/321k/Google-Trends/blob/master/Google%20Trends%20functions
O una versión propia de estas funciones. Saludos.