Cuando realizamos modelos hay 3 conjuntos de datos fundamentales:
- Conjunto de datos de entrenamiento: son los datos que entrenan los modelos
- Conjunto de datos de validación: selecciona el mejor de los modelos entrenados
- Conjunto de datos de test: Nos ofrece el error real cometido con el modelo seleccionado
Para entender mejor su importancia y como funcionan he preparado el siguiente esquema/ejemplo:
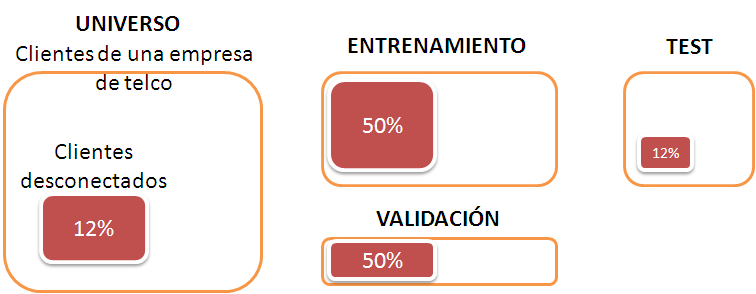
Una empresa de telecomunicaciones de cara a mejorar la efectividad de sus campañas comerciales decide realizar un modelo de propensión a la desconexión. Se define un universo como los clientes activos a ultimo día de un mes y se determina cuales de ellos han desconectado nuestra línea al mes siguiente. Podría ser recomendable utilizar varias cosechas de clientes para evitar efectos estacionales o campañas agresivas de la competencia. Para el universo seleccionado la tasa de desconexión se sitúa en un 12%. Este universo hemos de dividirlo en 2 partes. La primera de ellas formará el conjunto de datos de entrenamiento y validación y aquí es importante realizar un sobremuestreo estratificado del número de desconexiones para mejorar el entrenamiento del modelo. El estrato será tiene evento VS no tiene evento. En el esquema gráfico aumento la proporción de desconexiones hasta un 50%, no es una proporción imprescindible, si nuestra muestra no nos permite esa proporción algunos expertos con los que he trabajado y yo mismo aseguramos que un 20% de eventos puede ser suficiente; pero si es posible buscaremos el 50-50. En un árbol de decisión (por ejemplo) este sobremuestreo nos identificaría ramas extremas. Una vez definido el conjunto de datos sobremuestreado lo separamos en entrenamiento y validación. Este dinosaurio siempre deja la proporción 70-30…
El conjunto de datos de test será un subconjunto del universo inicial y es el que de verdad nos indica como funciona el error del modelo. Volviendo al tema de las cosechas para evitar la estacionalidad en el ejemplo concreto de desconexiones de clientes en operadora de telefonía podríamos emplear como test todos los clientes de otro mes distinto al que empleamos para la creación del universo inicial. Como sugerencia: entrenamos y validamos con el mes N, N+2 y N+4 y testeamos los resultados con N+1, N+3 y N+5.
La metodología de entrenamiento, validación y test nos permite aislar las relaciones aleatorias entre variables. Imaginemos que algún desequilibrado introduce en una máquina letra a letra el antiguo testamento en hebreo, tendremos un gran número de parámetros para un modelo y de forma aleatoria se pueden producir estructuras sintácticas debidas al azar. Si alguien detecta estas estructuras sintácticas, se inventa un código secreto y escribe un libro se puede hinchar a venderlo. Sin embargo aquellos que leen estas líneas no lo comprarán porque son conscientes del problema que supone tener un modelo con muchas variables y muchos parámetros.
Hola,
Yo estoy usando EM SAS y tengo una duda que ojalá pueda resolverme. Cuando se usa sobremuestra ¿es necesario hacer una corrección? antes de correr el modelo. Porque mi modelo con sobremuestra tiene mucho mejores resultados sin corrección(comparados con el evento en la realidad).
Gracias.
Mariza.
¿El sobremuestreo lo realizas antes de crear el INPUT DATA SOURCE?
Si tu conjunto de datos ya está sobremuestreado es evidente que tienes que hacer la corrección. Si el sobremuestreo lo has realizado con el EDIT TARGET PROFILE pestaña PRIOR seleccionando EQUAL PROBABILITY y con el SAMPLE y el DATA PARTITION entonces no es necesaria hacer la corrección.
Es un poco complejo lo que te cuento pero si estás trabajando con ello lo entenderás.
Si, lo hice después de el DATA SOURCE con SAMPLE (Estratificado y criterio igual).
Saludos.
Mariza.