He intentado permanecer ajeno a los datos del coronoavirus pero es imposible, sin embargo, me gustaría aprovechar para mostrar algunos trucos con R y Python. Esta vez en una sola entrada vamos a tratar las siguientes situaciones:
- Importar la tabla de worldometer sobre datos de países.
- Problemas con la librería OECD.
- Importar Excel con R.
- Not in con R.
- Gráficos de ranking ordenados con ggplot.
- Etiquetas en los scatter plot.
Importar la tabla de worldometer
Esta parte es probable que ya la haya puesto en otra ocasión, scraping sobre la web que tenemos todos en favoritos https://www.worldometers.info/coronavirus/
library(tidy verse) library(rvest) library(xml2) library(tm) url ='https://www.worldometers.info/coronavirus/' worldometers <- url %>% html()%>% html_nodes(xpath='//*[@id="main_table_countries_today"]') %>% html_table() worldometers <- worldometers[[1]] worldometers <- worldometers %>% rename(pais = `Country,Other` , muertes_habitante = `Deaths/1M pop`) %>% mutate(muertes = as.numeric(removePunctuation(TotalDeaths))) %>% select(pais,muertes_habitante, muertes)
Creamos un data frame con las variables necesarias
para realizar un ranking de porcentaje de muertes sobre millón de habitantes.
Problemas con la librería OECD
En este punto más que mostrar como leer datos de la OECD casi pido ayuda para entender la API y la librería. Si ejecutamos:
library(OECD)
salud <- search_dataset('health', data = get_datasets(), ignore.case = TRUE)
No encuentro la tabla SH.XPD.CHEX.GD.ZS que contiene Current health expenditure (% of GDP), el gasto en sanidad sobre % de PIB; tampoco he llegado a comprender bien la API para bajarme el XML o el Json, a los 45 minutos de lucha me rendí. Así que opte por descargar el Excel, tratarlo manualmente y leerlo.
Importar Excel con R
En este caso hay muchas entradas y muchas posibilidades pero me gustaría expresar una opinión, el mejor paquete para leer Excel es readxl, nada de Java por medio y la sintaxis no puede ser más sencilla:
ub = 'C:\\Users\\ API_SH.XPD.CHEX.GD.ZS_DS2_en_excel_v3.xls'
pib_salud <- read_excel(ub, sheet = 'Data')
names(pib_salud) = c('pais', 'pib_salud')
pib_salud <- pib_salud %>% mutate(pais = case_when(
pais == 'Iran, Islamic Rep.' ~ 'Iran',
pais == 'United Kingdom' ~ 'UK',
pais == 'United States' ~'USA' ,
TRUE ~ pais))
Descargué los datos en formato Excel de la tabla con ID SH.XPD.CHEX.GD.ZS En el propio Excel quité lo que sobraba y así pude crear un data frame y adaptar los nombres con case_when que pueden darme problemas a la hora de cruzar con worldometer.
Not in con R
Un código al que creo que ya he hecho mención en otras ocasiones pero que periódicamente aparece en el blog.
`%notin%` = Negate(`%in%`)
pinta <- worldometers %>% filter(pais %notin% c('Total:','World')) %>%
arrange(desc(muertes)) %>% filter(row_number()<=20)
pinta <- left_join(pinta, pib_salud)
La tabla de worldometer tiene un total y un mundo que hay que eliminar, de ahí el uso del not in, por otro lado no vamos a pintar los casi 200 países que tenemos nos vamos a quedar con los 20 con mayor número de muertes y por ello ordenamos de forma descendente con arrange y en filter ponemos row_number <= 20. También unimos los datos de muertes por millón de habitantes con los datos de PIB.
Gráficos de ranking ordenados con ggplot
Esta cuestión es recurrente cuando se trabaja con ggplot, es necesario ordenar los datos a representar, por defecto ggplot ordena por la variable x y en este caso sería una ordenación lexicográfica y necesitamos una ordenación numérica:
pinta %>%
mutate(País = fct_reorder(pais, muertes_habitante)) %>%
ggplot( aes(x=País, y=muertes_habitante)) +
geom_bar(stat="identity", fill="#908785", alpha=.5, width=.4) +
coord_flip() +
ylab("Muertes COVID por 1m. habitantes") +
theme_classic()
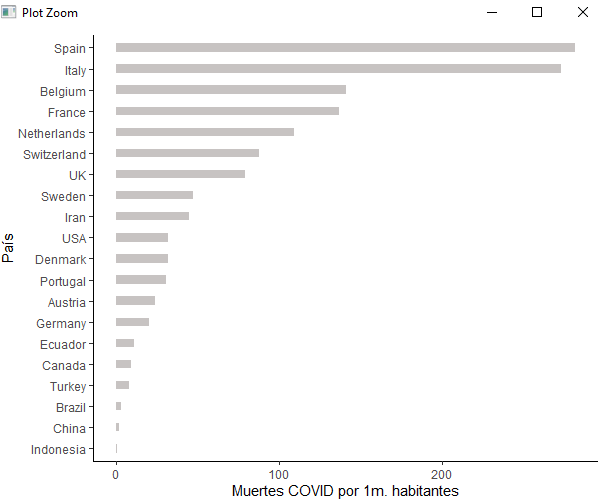
Si seguís el blog siempre suelo crear el objeto con los datos a pintar, no suelo emplear ggplot para hacer ni agregación ni filtrado, esto siempre vendrá en un objeto previo que en este caso se llama pinta y sobre él creamos la variable País (sin problemas con las tildes) y este País con fct_reorder le damos el orden que requerimos, en este caso ordenamos por muertes por millón de habitantes y ya realizamos el gráfico que deseamos:
De igual manera podemos realizar el gráfico de % de gasto en salud sobre PIB:
pinta %>%
mutate(País = fct_reorder(pais, pib_salud)) %>%
ggplot( aes(x=País, y=pib_salud)) +
geom_bar(stat="identity", fill="#908785", alpha=.5, width=.4) +
coord_flip() +
ylab("% gasto en salud sobre PIB") +
theme_classic()
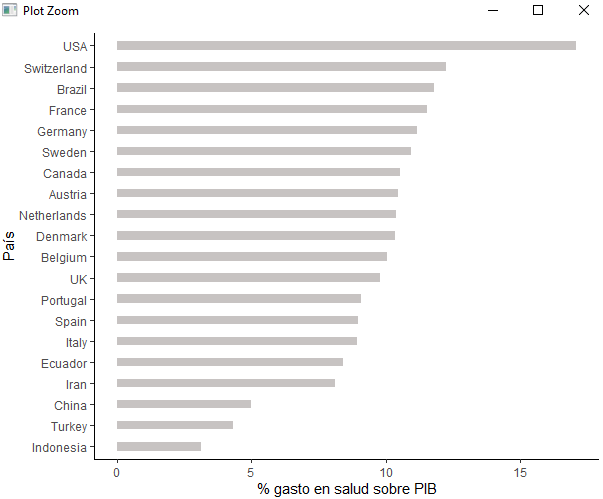
Se puede opinar que el % de gasto en salud sobre el PIB no es un dato apropiado porque los grupos de poder en USA distorsionan este dato (y arruinan familias), pero no quiero dejar en mal lugar a mi país y hay algún dato que deja en muy mal lugar al actual Gobierno. Ya hablaré.
Etiquetas en los scatter plot
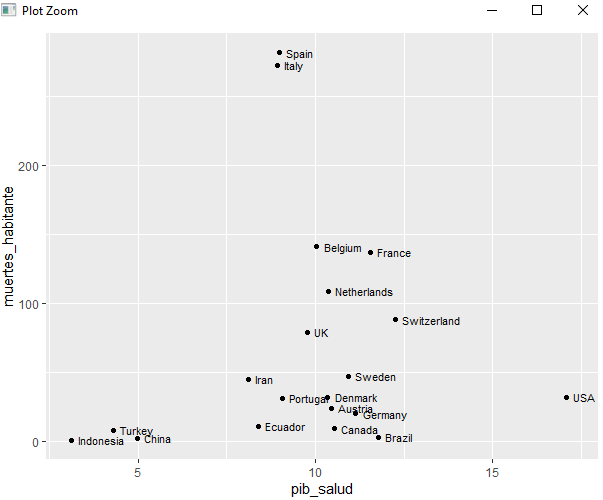
Que grandes gráficos de bivariables se hacen con ggplot. Además la sintaxis no puede ser más sencilla:
base <- ggplot(pinta, aes(x = pib_salud, y = muertes_habitante)) base + geom_point()
Sobre una base vamos añadiendo de lo más sencillo a lo más complicado. Añadimos las etiquetas de la forma más sencilla creando un vector que las contenga y empleando geom_text
paises <- pinta$pais base + geom_point() + geom_text(aes(label = paises), size = 3, hjust = 0, nudge_x = 0.2)
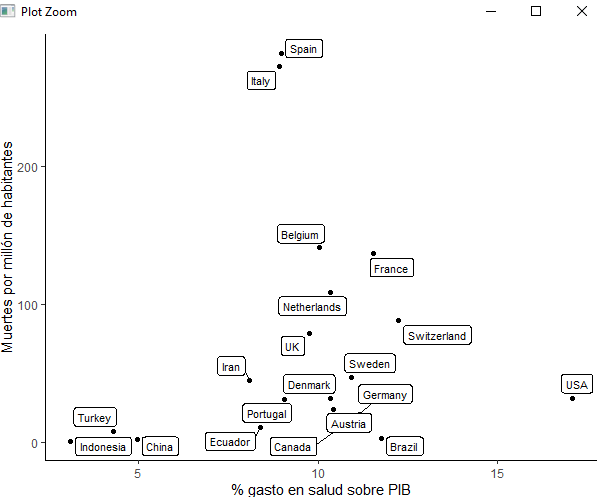
Sin embargo, en ocasiones tenemos que complicar mucho la sintaxis para que esas etiquetas queden “elegantes” pero la librería ggrepel viene en nuestra ayuda:
#install.packages("ggrepel")
library(ggrepel)
base + geom_point() +
geom_text_repel(aes(label = paises), size = 3)
base + geom_point() +
geom_label_repel(aes(label = paises), size = 3) +
ylab("Muertes por millón de habitantes") +
xlab("gasto en salud sobre % de PIB") +
theme_classic()
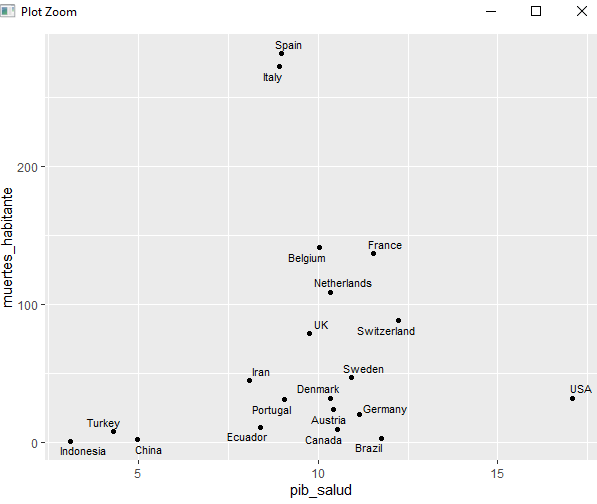
Que gran colocación de las etiquetas en el gráfico bivariable, podríamos añadirle más países y ponerle las cosas más difíciles.
Creo que es una serie de trucos muy útiles.