Muchos estudiantes terminarán trabajando con GLM que siguen buscando relaciones lineales en multitud de organizaciones a lo largo del planeta. Y hoy quería ayudar a esos estudiantes a interpretar los parámetros resultantes de un GLM, más concretamente los resultados de un PROC GENMOD de SAS aunque lo que vaya a contar ahora se puede extrapolar a otras salidas de SAS o R. En la línea de siempre no entro en aspectos teóricos y os remito a los apuntes del profesor Juan Miguel Marín. Con un GLM al final lo que buscamos (como siempre) es distinguir lo que es aleatorio de lo que es debido al azar a través de relaciones lineales de un modo similar a como lo hace una regresión lineal, sin embargo los GLM nos permiten que nuestra variable dependiente no sólo siga una distribución normal, puede seguir otras distribuciones como Gamma, Poisson o Binomial. Además un GLM puede trabajar indistintamente con variables categóricas y numéricas pero yo recomiendo trabajar siempre con variables categóricas y en la práctica cuando realizamos un modelo de esta tipo siempre realizaremos agrupaciones de variables numéricas. Si disponemos de variables agrupadas, de factores, los parámetros de los modelos nos servirán para saber como se comporta nuestra variable dependiente a lo largo de cada nivel del factor.
El modelo siempre fija un nivel base del factor, un nivel que promedia nuestros datos y el resto de niveles corrigen el promedio en base al coeficiente estimado. Imaginemos que modelizamos el número de abandonos en 3 carreras de coches, cuando la carrera se disputa en un circuito A el número de abandonos es 5, sin embargo en el circuito B son 10 y en el circuito C son 15. Si fijamos como nivel base de nuestro factor circuito el B tendríamos un modelo de este modo abandonos = 10 + 0.5*es circuito A + 1*es circuito B + 1.5*es circuito C + Error. El nivel base promedia nuestro modelo por lo que va multiplicado por 1 y el resto de niveles se corrigen por su multiplicador. Esta es la base de la modelización multivariante en el sector asegurador. Veamos en un ejemplo como se articulan los parámetros de estos modelos. Simulamos unos datos con la probabilidad de tener un siniestro por edad, zona y edad:
data datos_aleatorios;
do idcliente = 1 to 2000;
if ranuni(1) >= 0.75 then sexo = «F»;
else sexo=»M»;
edad = ranpoi(45,40);
if ranuni(8)>=0.9 then zona=1;
else if ranuni(8)>0.7 then zona=2;
else if ranuni(8)>0.4 then zona=3;
else zona=4;
output;end;
run;
data datos_aleatorios;
set datos_aleatorios;
if zona=1 then incremento_zona = 0.1+(0.5-0.1)*ranuni(8);
if zona=2 then incremento_zona = 0.1+(0.7-0.1)*ranuni(8);
if zona=3 then incremento_zona = 0.1+(0.2-0.1)*ranuni(8);
if zona=4 then incremento_zona = 0.1+(0.9-0.1)*ranuni(8);
incremento_edad=exp(1/edad*10)-1;
sini = (ranuni(9) – sum(incremento_zona, -incremento_edad))>0.8 ;
run;
Se da una probabilidad aleatoria de tener un siniestro que se ve incrementada o decrementada por la zona y la edad, el sexo, aunque aparece, no influye. El número de siniestros suponemos que sigue una distribución de poisson. Para entender mejor como funciona un GLM vamos a agregar los datos por los factores en estudio y contamos el número de clientes sumando el número de siniestros:
proc sql;
create table datos_agregados as select
sexo,
case
when edad<= 30 then «1 menos 30»
when edad<= 40 then «2 31-40»
when edad<= 50 then «3 41-50»
else «4 mas 50» end as edad,
zona,
log(count(idcliente)) as exposicion,
sum(sini) as sini
from datos_aleatorios
group by 1,2,3;
quit;
Nuestros datos tienen que ir ponderados por el logaritmo del número de clientes, será nuestro offset, ya que no es lo mismo tener un siniestro en un grupo de 2 clientes que un siniestro en un grupo de 20 clientes. Ponderados por el logaritmo porque siempre cuesta menos trabajar con números pequeños y además tienen unos superpoderes de los que no somos conscientes hasta que trabajamos con ellos. Ahora estos datos son los que emplearemos para el modelo:
proc genmod data=datos_agregados;
class sexo edad zona;
model sini = sexo edad zona / dist = poisson
link = log
offset = exposicion;
run;
GENMOD como todos los procedimientos de SAS necesita que le indiquemos las variables categóricas, en model especificamos el modelo y las opciones son los aspectos más interesantes. En dist especificamos la distribución de nuestra variable dependiente en link la función de enlace que vamos a emplear y como offset para ponderar la variable exposición que hemos creado a la hora de agregar los datos. Y los parámetros que estima este modelo son:
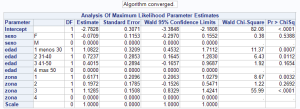
El intervalo de confianza de algunos estimadores contiene el valor 0, esos factores no son significativos como es el caso del sexo o bien puede haber agrupación de niveles de factores como es el caso de la edad entre 31 y 50 años o la zona 2 que puede unirse con otra zona. Vemos que el estimador del nivel base siempre es el último nivel del factor (esto puede cambiarse) y toma valores 0 y no 1 como habíamos usado en el ejemplo, para transformarlo en 1 sólo hemos de realizar el exponencial:
| Parameter | Estimate | |
| Intercept | 0.062 | |
| sexo | F | 0.932 |
| sexo | M | 1.000 |
| edad | 1 menos 30 | 2.951 |
| edad | 2 31-40 | 2.062 |
| edad | 3 41-50 | 1.494 |
| edad | 4 mas 50 | 1.000 |
| zona | 1 | 1.854 |
| zona | 2 | 1.218 |
| zona | 3 | 3.091 |
| zona | 4 | 1.000 |
| Scale | 1.000 |
Vemos que la zona 3 tiene casi el triple de siniestralidad que la zona 4 y lo mismo sucede con las edades jóvenes frente a las mayores edades, en cuanto al sexo que no fue significativo tenemos que las mujeres tienen un 7% menos de siniestralidad. Algunos resultados, aunque no salgan estadísticamente significativos, es evidente que pueden interesarnos comercialmente ya que mi producto puede dar un descuento a las mujeres y aunque sea pequeño se puede mantener, igual razonamiento para algunas zonas o grupos de edad susceptibles de unirse entre ellos. Este ejemplo es muy burdo pero aquellos que empiecen a trabajar con GLM se van a encontrar situaciones de este tipo, es necesario interpretar los parámetros estimados para describir como funciona el modelo pero igual de importante es la agrupación de factores y el posterior suavizado de los parámetros.
Quiero eliminar el salto de linea con SAS
Buen día Colegas, soy principiante en esto de SAS , quisiera su apoyo para poder encontrar la solución:
Quiero cargar una BBDD mas o menos 100,000 registros en 85 columnas , dentro de esas columnas hay 4 que son de texto , pero me encuentro que hay texto con salto de linea y al carga la base en SAS me lo interpreta como si fuer una linea mas .
me encontre esta solucion dentro del mismo foro :
data _null_;
length char 1.;
infile ‘BBDD.txt’ missover dsd lrecl=1 recfm=F ;
file ‘BBDD nueva.txt’ lrecl=1 recfm=F ;
input charASCII.;
if rank(char) =10 then char= «»;
put char;
run;
me funciona bien y todo pero cuando ya quiero leer » BBDD Nueva.txt »
no me arroja registros , como si no la estuviera leyendo.
Entonces abri el archivo «BBDD Nuevo.txt» en Note Pad ++ y me doy cuenta que este archivo esta en Macintosh (CR) y si lo cambio a Windows (CRLF) y guardo los cambios me lo lee sin problemas.
Como hago esto desde SAS Studio sin necesidad de irme a NotePad ++