Los modelos GLM son muy empleados en el ámbito actuarial para la obtención de modelos de riesgo, estos modelos de riesgo son los elementos fundamentales en el cálculo de tarifas y qué es una tarifa, imaginad el precio del seguro de vuestra vivienda, bueno pues es un cálculo en el que partiendo de un precio base se van añadiendo recargos y descuentos en función del tipo de riesgo que se quiera asegurar (recargos y descuentos en función de los metros cuadrados, de la ubicación de la vivienda de las calidades de construcción….). Esta es una visión muy simplista porque al final se tienen múltiples garantías y es necesaria la combinación de garantías, pero se puede entender de ese modo, un precio base al que recargamos o descontamos precio. Estos recargos y descuentos se denominan frecuentemente relatividades y hoy quiero acercaros a la obtención de esas relatividades y como un modelo GLM se transforma en el precio de un seguro.
En la línea habitual del blog vamos a ilustrar con un ejemplo usando unos datos muy conocidos para el trabajo con GLM y modelos de cálculo de tarifas. El primer paso es cargar el conjunto de datos en nuestra sesión de R:
library(dplyr)
varib <- c(edad = 2L, sexo = 1L, zona = 1L, clase_moto = 1L, antveh = 2L,
bonus = 1L, exposicion = 8L, nsin = 4L, impsin = 8L)
varib.classes <- c("integer", rep("factor", 3), "integer",
"factor", "numeric", rep("integer", 2))
con <- url("https://staff.math.su.se/esbj/GLMbook/mccase.txt")
moto <- read.fwf(con, widths = varib, header = FALSE,
col.names = names(varib),
colClasses = varib.classes,
na.strings = NULL, comment.char = "")
Los datos empleados pertenecen a una cartera de motocicletas, disponemos del número de siniestros (variable nsin), el importe de los siniestros (impsin), la exposición al riesgo de ese registro y una serie de factores que creemos pueden influir en la estimación del número de siniestros o del importe de los siniestros como son la edad, la zona, el nivel de bonificación,… Vamos a partir del modelo más sencillo, un modelo de frecuencia siniestral en base a un factor edad. Si realizamos con R un GLM clásico haríamos:
motoedad_factor <- case_when( as.numeric(motoedad) <=18 ~ 18, as.numeric(motoedad) >=60 ~ 60, TRUE ~ as.numeric(motoedad)) motoedad_factor <- as.factor(motoedad_factor) glm.1 <- glm(nsin ~ edad_factor+offset(log(exposicion)), data=filter(moto,exposicion>0), family=poisson()) summary(glm.1)
Hemos creado un factor edad que va desde los 18 años hasta los 60, realizamos una regresión de poisson para estimar el número de siniestros, como al final lo que deseamos es crear una proporción de siniestros de la forma nsin/exposición (frecuencia siniestral) lo que hacemos es poner el nsin como variable dependiente y la exposición como variable offset, la única variable regresora es la edad en formato factor, con este modelo obtendremos un estimador para cada nivel del factor. Es un modelo aditivo de la forma log(Y) = B0 + Edad18*B1 + Edad19*B2 + … + log(exp) + Error pero si realizamos el exponencial de los parámetros obtenidos con el modelo tendremos E[Y/exp] = B’0 * Edad18*B’1 * Edad19*B`2 * … Es decir, el valor esperado para la frecuencia siniestral es función de unos parámetros que recargan o descuentan esa frecuencia esperada. Esos B’ que son el resultado de exp(B) es lo que denominamos relatividades. Esto es muy utilizado para la realización de modelos de riesgo en el cálculo de tarifas.
Obtención de las relatividades
Reiterando, el exponencial del parámetro obtenido con la formulación del modelo es lo que denominamos relatividad y esa relatividad multiplicada por un término independiente nos daría como resultado la estimación de la proporción de siniestros, la estimación de la frecuencia siniestral para cada nivel del factor. También es relevante estudiar y comprender como R presenta esos parámetros, si hacemos el exponencial de los parámetros del modelo glm.1 que hemos hecho tenemos:
data.frame(exp(glm.1$coefficients))
exp.glm.1.coefficients.
(Intercept) 0.02986346
edad_factor19 0.48892314
edad_factor20 0.95974062
edad_factor21 0.73651804
….
¿Qué está pasando con la edad 18? Del término independiente pasa directamente a la edad 19 y de ahí hasta la edad 60, una estimación para cada nivel del factor a excepción del nivel 18. Bien, R considera al primer nivel del factor el nivel base, si lo vemos en forma de estimador un factor toma valor 1 si la observación está en ese nivel del factor y toma 0 si no lo está, pues si todos los estimadores presentes en el modelo toman el valor 0 el modelo estima que la proporción de siniestros en la edad 18 es de 0.02986, R no muestra ese estimador porque directamente no es necesario calcularlo, la edad 18 tiene una frecuencia siniestral del 3% la frecuencia del nivel base.
El elemento neutro de una multiplicación es el 1 así que fijado este nivel como base su relatividad ha de ser 1, ya que todos los demás multiplican por 0. Para la edad 19 la estimación que arroja el modelo es 0.0296 * 0.4889 = 0.0146 para ese nivel está aplicando un descuento y eso es lo que precisamente denominamos relatividad, el recargo o el decremento de la proporción.
Si queremos obtener las relatividades con nuestro modelo GLM de R tendríamos que realizar un proceso de este modo:
factor_reclasificado <- moto %>% group_by(edad_factor) %>% summarise(exp=sum(exposicion)) rela = exp(glm.1$coefficients) rela[1] <- 1 relatividades <- cbind.data.frame(factor_reclasificado,rela) row.names(relatividades) <- NULL
Sumarizamos los datos por exposición al riesgo, las relatividades son el exponencial de los parámetros pero hemos de recordar que el primer elemento es el término independiente cuya relatividad será 1, la forzamos, unimos expuestos por edad con el exponencial de los parámetros y obtenemos la tabla de relatividades. Estos datos se pueden graficar:
library(ggplot2) g2 <- ggplot(relatividades, aes(x=edad_factor)) + geom_col(aes(y=exp),fill="yellow",alpha=0.5) + geom_line(aes(y=rela * 5000), group=1, color="red") + scale_y_continuous(sec.axis = sec_axis(~./5000), name="") + theme_light()
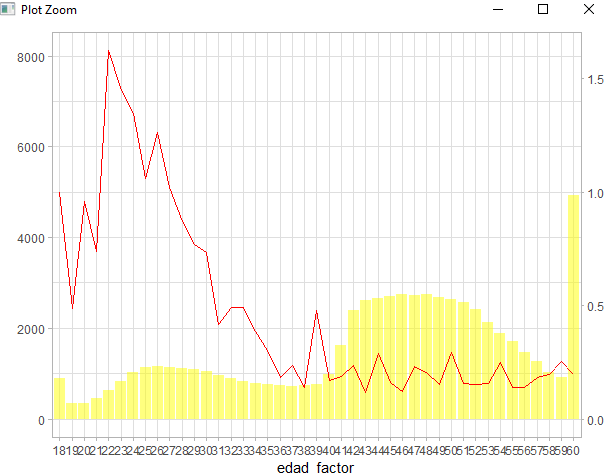
Si incluimos más factores en el modelo hay que tener en cuenta que el primer nivel del nuevo factor que pongamos en el modelo también será el nivel base y no tendrá su correspondiente estimador, incluyendo la zona podemos hacer lo siguiente para obtener las relatividades:
glm.2 <- glm(nsin ~ edad_factor+zona+offset(log(exposicion)), data=filter(moto,exposicion>0),
family=poisson())
summary(glm.2)
rela = data.frame(relatividad=exp(glm.2coefficients))
relanivel <- row.names(rela)
row.names(rela) <- NULL
zona = data.frame(glm.2xlevels[2])
zonanivel = paste0(names(zona),zona$zona)
zona <- left_join(zona,rela) %>% mutate(relatividad=ifelse(is.na(relatividad),1,relatividad))
factor_reclasificado <- moto %>% group_by(zona) %>% summarise(exp=sum(exposicion))
relatividades <- left_join(factor_reclasificado, zona)
Recordemos, el proceso no calcula es parámetro de los niveles base, por eso aparecen a nulo y lo que hacemos es asignar el elemento neutro de la multiplicación. Este código es bastante sucio pero que parece sencillo de parametrizar y así poder crear nuestra propia función de obtención y creación de gráficas de relatividades.
Si observamos las relatividades por edad aparecen “dientes de sierra” y es posible que nos encontremos con variaciones en los recargos y descuentos, para evitar esas fluctuaciones se emplean modelos GAM que nos permiten ajustar una función de suavizado sencilla antes de realizar la estimación, de este modo se obtienen relatividades más adecuadas o con más sentido de negocio, estas funciones se denominan splines y es un tema que abordaré a futuro. Espero que sea de utilidad.
Buenas,
Una pregunta, cuando uso la función predict(una vez hecho el modelo) sobre un dataset y la coloco como variable, ¿como interpreto ese output que me da a nivel fila? ¿Necesitaría usar exp sobre ese predict, para obtener un % de frecuencia siniestral estimada de cada observacion?
Un saludo y gracias!