Faltaban mapas de España con Python en el blog y hoy ilustro como hacerlos con geopandas y matplotlib, creo que una de las formas más sencillas de hacer este tipo de mapas. No debía de ser necesaria esta entrada puesto que la realización del mapa debería hacerse con QGis pero es posible que alguien necesite hacer un mapa de España por Comunidades Autónomas de manera rápida y sencilla en su sesión de Python. Es necesario comentar que este trabajo está hecho con Ubuntu, en un entorno Windows la instalación del paquete geopandas es un dolor de cabeza.
Shapefile
El primer paso para la realización del mapa es la obtención del shapefile desde GADM. No he encontrado un paquete de Python que realice esta tarea como sucede con R. Una vez lo hayamos descargado empezamos creando nuestro data frame con la información del shape file:
import geopandas as gpd import matplotlib.pyplot as plt # Filepaths ub_shp = '/home/rvaquerizo/Mapas/gadm36_ESP_shp/gadm36_ESP_1.shp' # Read files espania = gpd.read_file(ub_shp, encoding='utf-8') espania.head()
Reseñar que el mapa de GADM a nivel de Comunidad Autónoma
es el nivel 1 por ello leemos gadm36_ESP_1, la división administrativa correspondiente a las Comunidades Autónomas es la 1, provincias 2, comarcas 3 y municipios 4. Os los descargáis una vez, podéis mover Canarias y así tenéis un gráfico adecuado.
Datos de densidad de población en España
No lo he comentado hasta ahora pero el dato que deseamos representar es el dato de densidad de población en España, además nos servirá para hacer scraping de la web de datosmacro que tanto uso:
import pandas as pd from bs4 import BeautifulSoup import requests import re import time import string
El scraping de la tabla de densidades de población por Comunidad Autónoma lo vamos a llevar a cabo con BeatifulShop, creo que es la forma más sencilla:
url = 'https://datosmacro.expansion.com/demografia/poblacion/espana-comunidades-autonomas' pagina = requests.get(url) soup = BeautifulSoup(pagina.content, 'html.parser')
tbl = soup.find("table",{"id":"tb1"})
df = pd.read_html(str(tbl))[0]
df = df[['CCAA', 'Densidad']]
df.head()
Es evidente que necesitamos trabajar los textos, pero esperamos a unir los datos al mapa.Veamos como están definidas las Comunidades Autónomas en los conjuntos de datos de trabajo:
df.CCAA.unique() espania.NAME_1.unique()
Reemplazamos el conjunto de caracteres [+] por nada y cambiamos los nombres de las comunidades que no sean iguales:
df['CCAA'] = df['CCAA'].map(lambda x: x.replace(' [+]', ''))
import numpy as np
espania['NAME_1'] = np.where(espania['NAME_1']=='Castilla-La Mancha','Castilla La Mancha',espania['NAME_1'])
espania['NAME_1'] = np.where(espania['NAME_1']=='Comunidad Foral de Navarra','Navarra',espania['NAME_1'])
espania['NAME_1'] = np.where(espania['NAME_1']=='Ceuta y Melilla','Ceuta',espania['NAME_1'])
espania['NAME_1'] = np.where(espania['NAME_1']=='Islas Canarias','Canarias',espania['NAME_1'])
espania['NAME_1'] = np.where(espania['NAME_1']=='Región de Murcia','Murcia',espania['NAME_1'])
espania['NAME_1'] = np.where(espania['NAME_1']=='Comunidad de Madrid','Madrid',espania['NAME_1'])
espania['NAME_1'] = np.where(espania['NAME_1']=='Islas Canarias','Canarias',espania['NAME_1'])
espania['NAME_1'] = np.where(espania['NAME_1']=='Principado de Asturias','Asturias',espania['NAME_1'])
Prefiero emplear el nombre del conjunto de datos de datosmacro por ser más corto. Una vez los nombres sean iguales podemos hacer la left join de los dos dataframes y pintar el mapa:
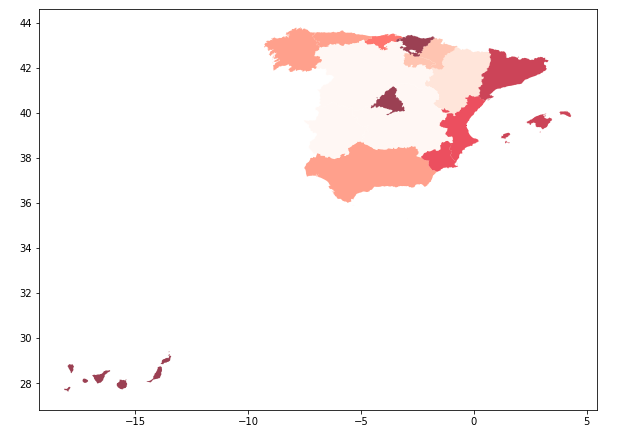
espania = espania.merge(df, left_on=['NAME_1'],right_on=['CCAA'], how='left') plt.rcParams["figure.figsize"]=20,20 my_map = espania.plot(column="Densidad", linewidth=0.3, cmap="Reds", scheme="quantiles", k=8, alpha=0.7)0
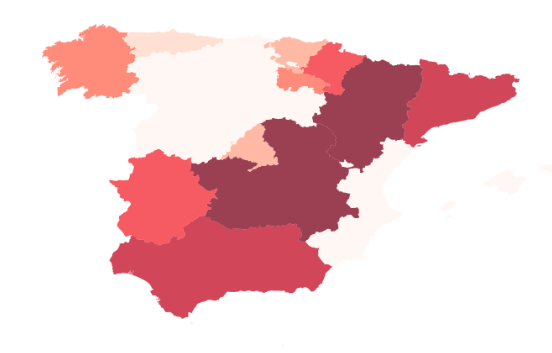
Ya tenemos nuestro gráfico y podemos representar datos sobre la incidencia del COVID por Comunidad Autónoma relativizando por densidad de población.
Casos de COVID 19 por densidad de población
datadista = "https://raw.githubusercontent.com/datadista/datasets/master/COVID%2019/ccaa_covid19_casos.csv" casos = pd.read_csv (datadista)
Siempre el homenaje a Datadista, ese no puede faltar.
casos = casos.iloc[:, [1,-1]]
casos.columns = ['CCAA', 'casos']
casos.head()
espania = espania.merge(casos, left_on=['NAME_1'],right_on=['CCAA'], how='left')
espania['tasa_densidad'] = espania['casos']/espania['Densidad']
my_map = espania.plot(column="tasa_densidad", linewidth=1, cmap="Reds", scheme="quantiles",
k=8, alpha=0.7)
Obtenemos el mapa con el que comienza la entrada. Canarias siquiera aparece, los casos por densidad de población son mínimos y en el extremo opuesto tenemos a Castilla la Mancha y a Aragón.