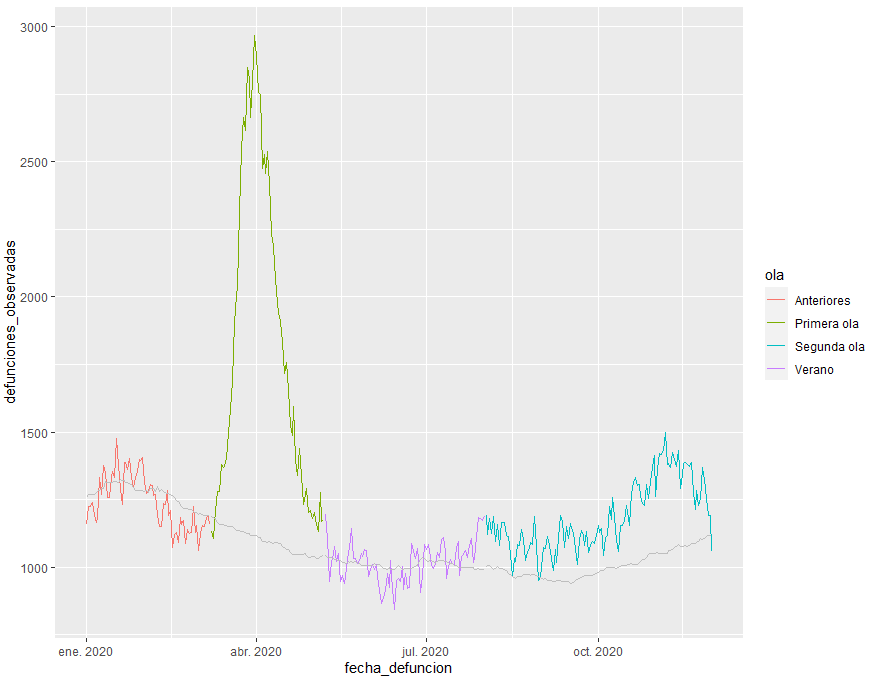
Me cuesta hablar sobre COVID porque creo que hay voces con más conocimiento y mejor preparadas que la mía para opinar sobre el tema. Pero en los últimos tiempos leo algunas cosas que me empiezan a calentar y vuelvo a pensar que a lo mejor mi voz si debió ser escuchada. El caso es que hay una línea de opinión que argumenta que estamos más o menos igual que en el momento de aparición del virus, algo que llamamos primera ola frente a segunda ola, que las medidas no han funcionado siempre con el argumento «yo no soy contrario a pero en la Universidad de Nabucodonosor salió un estudio que». Sería bajo y de mala educación por mi parte insinuar que son unos gilipollas y por eso prefiero presentar un pequeño código de R para que podáis leer los datos de MoMo del Instituto Carlos III:
library(tidyverse)
library(lubridate)
df <- read.csv("https://momo.isciii.es/public/momo/data")
df <- df %>% filter(ambito=='nacional' & nombre_sexo=='todos' & cod_gedad=='all') %>%
mutate(fecha_defuncion=as.Date(fecha_defuncion, '%Y-%m-%d')) %>%
filter(year(fecha_defuncion)>=2020)
df <- df %>% mutate(ola = case_when(
fecha_defuncion <= as.Date("2020-03-07") ~ 'Anteriores',
fecha_defuncion <= as.Date("2020-05-07") ~ 'Primera ola',
fecha_defuncion <= as.Date("2020-08-01") ~ 'Verano',
TRUE ~ 'Segunda ola'),
exceso = defunciones_observadas - defunciones_esperadas)
ggplot(data=df, aes(x=fecha_defuncion, y=defunciones_observadas,group=ola, fill=ola, color=ola)) + geom_line() +
geom_line(aes(x=fecha_defuncion, y=defunciones_esperadas), color="grey")
df %>% group_by(ola) %>% summarise(exceso = sum(exceso))
Comentarios: No tengo ni idea del número de muertes que provoca el COVID (no soy el único) por eso fijo el término exceso como el número observado – número esperado, las fechas de las olas me las he imaginado y he querido poner un par de meses llamados verano en los que veníamos del periodo de confinamiento. Ejecutad el código y…
ola exceso
1 Anteriores -1653.
2 Primera ola 44243.
3 Segunda ola 21730
4 Verano 1059.
Eso no es estar igual.