Más ejemplos de uso del paquete de R XML. Vamos a leer datos del data warehouse del European Central Bank. Si dais una vuelta por la web tendréis interesantes datos económicos de los países de la Unión Europea. A modo de ejemplos vamos a leer los datos de los tipos de interés medios a 12 meses que se están dando por los bancos en España y la evolución del Euribor a 6 meses.
– Report Tipos: http://sdw.ecb.europa.eu/quickview.do?SERIES_KEY=124.MIR.M.ES.B.L22.F.R.A.2250.EUR.N
– Report Euribor: http://sdw.ecb.europa.eu/quickview.do?SERIES_KEY=143.FM.M.U2.EUR.RT.MM.EURIBOR6MD_.HSTA
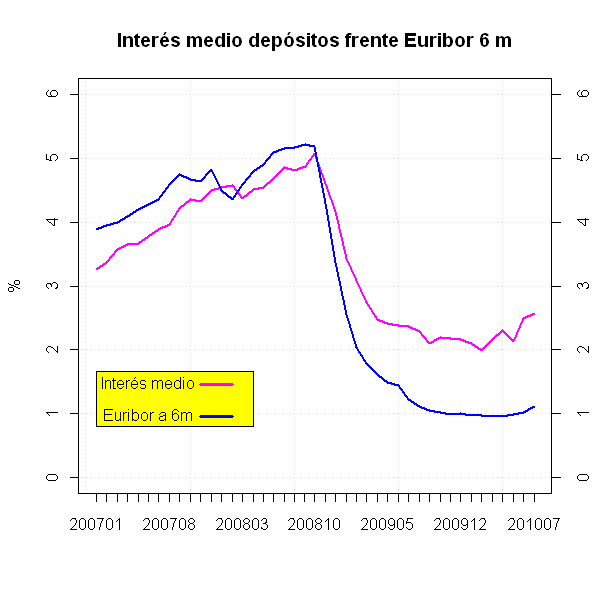
Vamos a generar el siguiente gráfico comparativo:
Comenzamos el trabajo con R:
require(XML)
pag="http://sdw.ecb.europa.eu/quickview.do?SERIES_KEY=124.MIR.M.ES.B.L22.F.R.A.2250.EUR.N"
depos=readHTMLTable((((pag))))
#str(depos)
#Creamos un data frame legible
aux1=data.frame(depos[6])
#Eliminamos títulos
aux1=aux1[4:nrow(aux1),]
#Prefiero trabajar con 2 df
mes=as.vector(aux1NULL.V1)
#Transformo un factor de R a número
valor=as.data.frame(as.numeric(
levels(aux1NULL.V2)[aux1NULL.V2]))
#Creo el df final
depos=data.frame(cbind(mes,valor))
#No quiero factores por ningún sitio
deposmes=as.character(depos$mes)
str(depos)
names(depos)=c("mes","interes")
head(depos)
Es un código sucio, no me he preocupado mucho por él. Con la función readHTMLTable leemos la tabla del report que nos ofrece el BCE. STR es muy importante porque nos quedaremos con la parte del objeto que nos interesa, los datos, y no siempre están en la misma posición, en alguna otra lectura me he encontrado esta problemática, en este caso seleccionamos el elemento 6. Nos quedamos con las fechas por un lado y los datos por otro, le damos el formato que mejor se adecúa y ya tenemos un objeto con mes y tipo medio. De forma análoga lo hacemos con el Euribor a 6 meses:
pag2="http://sdw.ecb.europa.eu/quickview.do?SERIES_KEY=143.FM.M.U2.EUR.RT.MM.EURIBOR6MD_.HSTA"
eur6m=readHTMLTable((pag2))
aux1=data.frame(eur6m[6])
#Eliminamos títulos
aux1=aux1[4:nrow(aux1),]
#Prefiero trabajar con 2 df
mes=as.vector(aux1NULL.V1)
#Transformo un factor de R a número
valor=as.data.frame(as.numeric(
levels(aux1NULL.V2)[aux1NULL.V2]))
#Creo el df final sin factores
eur6m=data.frame(cbind(mes,valor))
eur6mmes=as.character(eur6m$mes)
str(eur6m)
names(eur6m)=c("mes","eur6m")
head(eur6m)
Si alguien quiere crear una función leeBCEdw…Ya tenemos dos objetos R uno con los tipos medios de depósitos de la banca española y otro con el evolutivo del Euribor, se me ocurre que podíamos pintar una serie comparativa de ambos datos desde 2007, un año antes de la debacle del sistema financiero. Preparamos el objeto:
#Acotamos el número de meses de la serie
depos=subset(depos, mes >= "2007")
eur6m=subset(eur6m, mes >= "2007")
#Unimos ambas series
datos=merge(depos,eur6m,by.x="mes",by.y="mes",all.x)
¡Listo! un data frame preparado para trabajar, pero el mes tiene un formato carácter y es necesario darle formato fecha para poder realizar una serie:
#Damos un formato apropiadao a las fechas
Sys.setlocale("LC_TIME", "English")
#Todo en minúsculas
aux1=tolower(paste(datos$mes,"01",sep=""))
aux2=as.Date(aux1,"%Y%b%d")
#Volvemos a cambiar la configuración de fechas
Sys.setlocale("LC_TIME", "spanish")
#Meses en formato YYYYMM
mes=(as.numeric(format(aux2, format = "%Y"))*100
+ as.numeric(format(aux2, format = "%m")))
#Creamos el DF final
datos=cbind(mes,subset(datos,select=c("interes","eur6m")))
head(datos)
#Tenemos que realizar una ordenación
library(reshape)
datos<-sort_df(datos,vars='mes')
En un mensaje anterior ya trabajamos con los formatos de las fechas y la configuración local. Esa misma metodología empleamos ahora. Establecemos la fecha a English con SYS.SETLOCALE y añadimos un 01 para crear la fecha. Particularmente prefiero los formatos de fecha del tipo AAAAMM y para ello empleamos FORMAT, creo que es un buen ejemplo de uso de fechas en R pasadas a número. Por último aprovechamos la librería RESHAPE para ordenar el data frame resultante que tiene muy buena pinta. Ahora toca graficar:
win.graph()
plot(datosinteres,ylim=c(0,6),type="l",lwd=2,
xaxs="r", yaxs = "r", xaxt="n", yaxt="n",
ylab="%",col=14,xlab="",panel.first = grid(lwd=1),
main="Interés medio depósitos frente Euribor 6 m")
points(datoseur6m,type="l",col=12,lwd=2)
axis(1,1:nrow(datos),datos$mes)
axis(2); axis(4)
#Añadimos la leyenda
polygon(c(1,16,16,1),c(0.8,0.8,1.65,1.65),col=15)
text(6,1.5,"Interés medio")
points(c(rep(NA,10),rep(1.45,4)),type="l",lwd=3,col=14)
text(6,1,"Euribor a 6m")
points(c(rep(NA,10),rep(0.95,4)),type="l",lwd=3,col=12)
Tenemos un buen ejemplo de creación de ejes personalizados con AXIS. Para personalizar los ejes yo recomiendo usar las opciones xaxs=»r», yaxs = «r», xaxt=»n», yaxt=»n» en plot. Es curioso lo que me ha costado trabajar con la función polygon para hacer una simple cajita. Pero os dejo una forma “curiosa” de crear la leyendas para que dispongáis de otros métodos de graficar con R. Ahora me queda comentar un poco el gráfico. Decidme que no estáis asustados. Hasta 2009 los bancos daban unos intereses en sus depósitos por debajo del Euribor a 6 meses pero ahora están dando depósitos a pérdidas. La batalla del pasivo está haciendo que las entidades bancarias cada vez den más depósitos con márgenes negativos. Este tema merece una lección de economía del ignorante porque en España el poder financiero controla el poder industrial y el Banco de España está dejando que la banca se harte a realizar emisiones propias…