‘Random walk’ hace referencia a la teoría financiera de que los mercados financieros siguen un camino aleatorio. Pero NO vamos discutir si se da o NO se da tal hipótesis, lo que SÍ vamos a hacer es utilizar R para seguir las acciones, fondos de inversión, o sencillamente para ver nuestro decepcionante Euro respecto a otras divisas (por si algún día los ‘españolitos’ debieramos empezar a emigrar de nuevo… tal como esta el patio!).
Vamos a necesitar varios paquetes, si no me olvido de ninguno, básicamente son estos 2:
-quantmod
-tawny
La manera de funcionar es que conectan a la fuente de datos de los portales de Yahoo y Google, y extrae los datos que le pidamos con unos 15-30 minutos de retraso respecto al tiempo real de mercado (creo que conecta con Yahoo por defecto). Sea como sea, nos indica tambien la fecha y hora de la última cotización más reciente.
Es tan sencillo como hacer:
> getQuote(‘AAPL’)
..y nos informa de la última cotización de las acciones de APPLE.
El ligero inconveniente es que siempre vamos a depender de la conectividad a Yahoo o Google, si ellos dejan de recibir datos, nosotros tambien. Un apunte importante, para las acciones americanas solo basta escribir su ‘ticker’ (código de 3 o 4 letras que identifica a las acciones de una compañía) tal cual, pero para el resto de paises es otra historia, hemos de añadir su ‘destino’. Aquí os facilito una breve guía:
.MC para el Mercado Continuo español.
.PA si cotiza en Paris
.DE si cotiza en Alemania (Deutschland)
.MI si cotiza en Milan
.LS si cotiza en Lisboa
Así tenemos, por ejemplo (CITIGROUP, BANCO SANTANDER, BNP PARIBAS, DEUTSCHE BANK, BANCO ESPIRITU SANTO):
> getQuote(‘C+SAN.MC+BNP.PA+DBK.DE+BES.LS’)
La lista de valores la podemos separar por ‘;’ o ‘+’, aunque creo que NO es la única manera.
Veamos un listado de índices europeos (4), americanos (3) , Japón, Brasil y algunos pares de divisas:
>getQuote(‘^IBEX;^GDAXI;^FCHI;^STOXX50E;^DJI;^IXIC;^GSPC;^N225;^BVSP;
EURUSD=X;GBPEUR=X;USDJPY=X’)
La función ‘getQuote’ solo nos informa de la cotización más reciente. Para extraer un histórico lo mejor es usar ‘getSymbols’ especificando el inicio y final de fechas, si NO indicamos final extrae hasta el último cierre de día (este histórico NO incluye la cotización del día presente en curso), y si NO especificamos el inicio de la serie histórica nos dará el primer día de enero de 2007. Para estar seguros siempre podemos acudir a la función ‘head’ y ver unas líneas del inicio de la serie o bien ‘tail’ para ver los días más recientes. Ejemplo con las ‘Starbucks’:
> getSymbols(«SBUX»)
> head(SBUX)
> tail(SBUX)
Si queremos extraer un detalle de los últimos meses (formato de fechas «yyyy-mm-dd»):
> getSymbols(«SBUX»,from=»2010-01-01″)
y ahora llega lo mejor, vamos a confeccionar su gráfico ‘chart’ , y sin cerrar la ventana-salida, creamos algunos de sus indicadores (RSI, Bollinger Bands y ADX):
> chartSeries(SBUX)
> addRSI()
> addBBands()
> addADX()
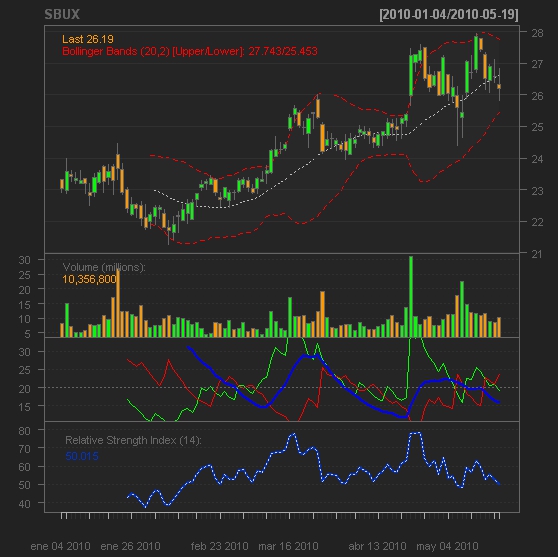
…y guardamos el gráfico en ‘.PDF’:
> saveChart(.type = «pdf», dev = dev.cur())
chart saved to SBUX.pdf
Si quisieramos concretar el rango temporal basta con definirlo (ejemplo sólo año 2009):
> getSymbols(«SBUX»,from=»2009-01-01″,to=»2009-12-31″)
Para filtrar la información (columnas) a extraer podemos usar la función ‘yahooQF()’:
> getQuote(‘TEF.MC’,what=yahooQF())
Podemos tambien conocer el histórico de dividendos que una compañía ha repartido a sus accionistas:
> getDividends(‘SBUX’)
O bien conocer los rendimientos diarios de los últimos 30 días o desde un fecha anterior hasta fecha reciente:
> getPortfolioReturns(«SBUX», obs = 30)
> getPortfolioReturns(«SBUX», start = «2010-03-01», end = Sys.Date())
Lo que tenemos que TENER MUY CLARO es que cada vez que usemos el ‘ticker’ para cualquier función gráfico a extraer, éste hace referencia al objeto memorizado de la última vez que lo definimos como símbolo con ‘getSymbols’.
Si cambiamos el rango temporal a uno muy corto, solo ‘graficaremos’ un chart sobre ese corto espacio temporal, su respectivo histórico de dividendos tambien estará sujeto a dicho espacio, etc.
Para extraer un listado completo de compañías, por ahora que yo sepa solo existe esta posibilidad para los indices DOW JONES y SP500:
> getIndexComposition(‘^DJI’)
> getIndexComposition(‘^GSPC’)
En caso de ignorar algun ‘ticker’ o el código de algún índice o cualquier producto financiero, lo mejor es remitirse a Yahoo y/o Google.Como hemos visto, lo que aquí R nos puede ofrecer es la facilidad de seguir un listado de ‘stocks’ y/o índices de diferentes países, divisas, conocer su histórico (lo podemos reducir a rangos cerrados de años atras), y sobretodo graficar ‘charts’ con sus indicadores técnicos ‘chartistas’ sin coste alguno (hay quienes pagan por aplicaciones tipo MetaStock), aunque uno muy bueno para ‘stocks’ americanos se ofrecen gratis en:
www.stockcharts.com
No así en Europa, donde es difícil tener juntos ‘stocks’ de tan diferentes mercados (y a veces gráficos muy pobres). Bastante bueno pero pobre en gráficos:
www.boursorama.com
Algunos fondos para estar cortos y beneficiarse de caídas del mercado (‘CZI’,’FAZ’,LHB’,ERY’…) o bien el ‘VXX’:
> getSymbols(«VXX»,from=’2009-01-01′)
> chartSeries(VXX)
un saludo
…y ya saben, ‘Random’ tambien se escribe con R.
Dani Fernández.
Espectacular entrada.
A mi me llegó una demo de una aplicación basada en R que hacía justo lo que nos muestras. Pero se conectaba a Bloomberg. ¿Sólo se conecta a Yahoo y Google? De todos modos me parece más que suficiente.
Ahora nos queda hacer un modelo de predicción de cotizaciones basado en noticias.
Gracias Raul!
Sí, tambien conecta a Bloomberg, por lo que habría que remitirse a sus códigos ‘ticker’ propios. Aún así, lo más habitual es conectar
a Yahoo.
Por lo de crear un modelo que prediga el mercado, NO conozco ninguno válido; lo que SÍ se lleva es programar algoritmos para hacer trading automático (como el ‘flash crash’ que hizo caer casi 1000 puntos al índice DOW hace 2 semanas) conocido como algo-trading, se porgraman y se deja a las ‘maquinitas’ lanzar miles de ‘trades’ en nanosegundos, usualmente programados en C++ y java:
http://www.quantfinancejobs.com
En breve inserto otro tutorial ‘rompedor’.
un saludo!
Sinceramente impresionantes los gráficos.
Muy buena la entrada. ¡Felicidades!
Hola,
Esta información me es MUY útil en este momento! He tenido una experiencia regular con la búsqueda de este tipo de información en la web, sobre todo por mi falta de experiencia y conocimientos de la terminología que se maneja en finanzas. Pero con esta entrada «veo la luz»!!
Estoy enamorado del paquete quantmod:
library(quantmod)
getSymbols(«SLR.MC»,from=»2010-05-01″)
chartSeries(to.weekly(SLR.MC),up.col=’white’,dn.col=’blue’)
¡Es que es acojonante!
Por cierto, tengo que poner un truco que me ha contado Carlos para que podamos usar este paquete en el trabajo, ya que muchas empresas cierran el puerto 80 pero tienen abierto el 8080.
Vamos a juntar entre todos pasta y vamos a comprar oro:
#library(quantmod)
loadSymbols(‘GLD’)
chartSeries(GLD)
¡Alucinante! ¿Os imagináis que algún ministro de economía hubiera vendido parte de las reservas de un país en 2007? ¡Vaya ruina!
Pues sí, el mismísimo Gobierno de Ejjpaña se deshizo de gran parte de ellas en 2007. Ello obedecía a que entendía que no hacía falta mantener tantas reservas de oro si ya no existe una moneda nacional (la peseta) que sostener, dado que el la sostenibilidad del euro corresponde realmente al BCE. Por otro lado, todo parece indicar que en 2007 empezó a subir el deficit por cuenta corriente por lo que decidió hacer caja desprendiendose de 2/3 de sus reservas respecto a las que mantenía en 2002.
http://www.elmundo.es/mundodinero/2007/09/16/economia/1189942972.html
http://www.cotizalia.com/cache/2007/05/25/98_banco_espana_venta_mayor_parte_reservas.html
Hola a todos, hoy mismo he descubierto este blog y me ha parecido fantástico.
En cuanto a los modelos de predicción existen unos tipos de modelos, como los procesos estocásticos de difusión que su utilizan para modelizar el crecimiento, además existe una variante que se utiliza en finanzas que son los procesos de difusión de salto o con salto, no se bien como traducirlos en inglés son «jump-diffusion models», y están basados en la modelización de procesos estocásticos.
Muy buen articulo, quería decirles que pese a no participar, su blog es uno de los poco que sigo diariamente. Saludos! Romina
If you desire to get much from this piece of writing then you have to apply
these strategies to your won blog.
Excellent way of explaining, and pleasant paragraph to take data on
the topic of my presentation subject, which i am going to convey in university.