El bootstrap es una técnica de muestreo que, a partir de la simulación, crea sucesivas muestras con reemplazamiento que teóricamente son una buena aproximación al universo muestral. Por aquí podéis encontrar información y bibliografía al respecto. Lo que yo quería comentaros hoy es algo a lo que ya hizo referencia la comunidad de SAS en español. Hacer bootstrap con SAS no es complicado. Cuando buscas información ves unas macros que dan miedo y piensas “esto es un software”, sin embargo el tema no es tan difícil y con un paso DATA ya podemos poner a funcionar esta técnica. Veamos el ejemplo, partimos de un conjunto de datos SAS que obtenemos en esta web interesantes ejemplos verdad. Nos bajamos el archivo a una ubicación de nuestra máquina o leemos la url y comenzamos a trabajar:
Data poissonreg;
infile "c:\temp\poissonreg.csv" delimiter="," firstobs=2;
input id school male math langarts daysatt daysabs;
run;
Tenemos un dataset con 7 variables, el id alumno, la escuela, el sexo, la nota en matemáticas, la nota en lenguaje, los días en clase y los días ausentes en clase. El dataset tiene 316 observaciones, se trata de crear 100 muestras de tamaño el 90% del dataset de partida y estudiar la nota media por escuela y sexo de las muestras extraídas. En total tendremos que tener 285*100 observaciones:
*PARAMETROS SENCILLOS;
%let numero_muestras=100;
%let porcen_seleccion=0.9;
*DATASET CON REMUESTREO;
data boot;
do muestra=1 to &numero_muestras.;
do i=1 to ceil(316*&porcen_seleccion.);
sel=ceil(ranuni(0)*316);
set poissonreg point=sel;
*SOLO LA OBSERVACION SELECCIONADA;
if _n_>1 then stop;
else output;
end;
end;
run;
No puede ser más sencillo. Recorremos el dataset y sacamos tantas muestras como indicamos del tamaño que deseamos. Evito parametrizar el código para facilitar su comprensión. Podemos aproximarnos a los errores cometidos con las estimaciones obtenidas, de forma muy simple:
proc sql;
select mean(math)
from poissonreg;
*MEDIAS DE 10 EN 10;
select int(muestra/10) as muestra,
mean(math)
from boot
group by 1;
quit;
Sé que esta validación no tiene mucha argumentación matemática, pero podemos ver que las medias no difieren en gran medida, sólo nos sirve de aproximación. Incluso gráficamente podemos analizar como funciona la estimación por remuestreo por alguna de las categorías presentes en nuestro estudio:
data vista/view=vista;
set boot poissonreg (in=a);
label comb="School _ Male";
comb=compress(put(school,z2.)||"_"||put(male,z2.));
clase=int(muestra/10);
if a then do;
clase=100;
math2=math;
end;
proc sgplot data=vista;
vline comb/ response=math stat=mean group=clase ;
*MODIFICAMOS LOS DATOS OBTENIDOS PARA ANALIZAR LOS
INTERVALOS DE CONFIANZA;
vline comb/ response=math2 group=clase stat=mean
lineattrs=(thickness=2) limitstat=clm;
quit;
Creamos una vista que es la unión de las estimaciones por bootstrap con los datos. Agrupamos las categorías para obtener las estimaciones por escuela y sexo. Hacemos un artificio para identificar correctamente los datos de nuestro universo. A cada estimación le asignamos una clase. El PROC SGPLOT pinta todas las estimaciones por grupo y además añadimos otra línea con los intervalos de confianza del universo muestral.
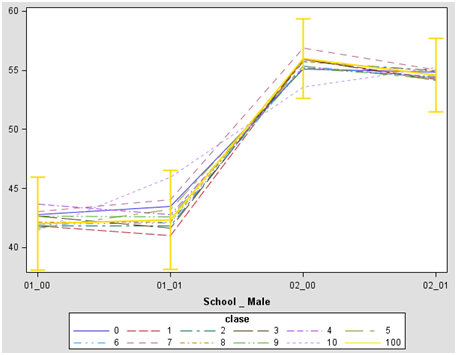
Vemos que las estimaciones obtenidas por bootstrap están dentro de los intervalos de confianza. El remuestreo no es complicado con SAS, siempre es más complicado el diseño. Saludos.
Está feo que yo me lo diga a mi mismo. Pero ojo que es simple y sencillo hacer esto.