En los últimos tiempos estoy empeñado en usar redes neuronales para la tarificación en seguros. Históricamente la tarificación de seguros, el pricing, se ha basado en modelos lineales generalizados GLM (sus siglas en inglés) porque su estructura es sencilla, se interpreta bien y no olvidemos que el sector asegurador está regulado y es necesario elaborar una nota detallada de cómo se articula una tarifa y el GLM nos ofrece una estructura multiplicativa que se comprende y con la que los reguladores se sienten muy cómodos. Sin embargo, una red neuronal es el paradigma de «caja negra», ¿cómo podemos saber que hace esa caja negra? Estoy trabajando en ello, la descripción del funcionamiento de las ponderaciones de una red está muy arriba en la lista de mis tareas pendientes.
Pero esta entrada del blog va encaminada a describir de forma como las neuronas de una red neuronal salvan la linealidad y como un mayor número de neuronas son capaces de ajustar mejor a una estructura compleja y si llegamos a describir como funciona esa estructura compleja podremos usar estas técnicas para realizar tarifas de riesgo.
Como siempre, para ilustrar el funcionamiento se emplea un ejemplo muy sencillo:
[sourcecode language=»r»]#Variable independiente
indep = runif(500,100,3000)
#Función para crear la variable dependiente
foo = function(x){ mean(x)*(1-sin(-0.006042*x)+sqrt(x/100))
}
dep = sapply(indep,foo)
dep=dep+(runif(length(dep),-500,500))
dep = as.matrix(dep)
indep = as.matrix(indep)
plot(indep,dep)[/sourcecode]
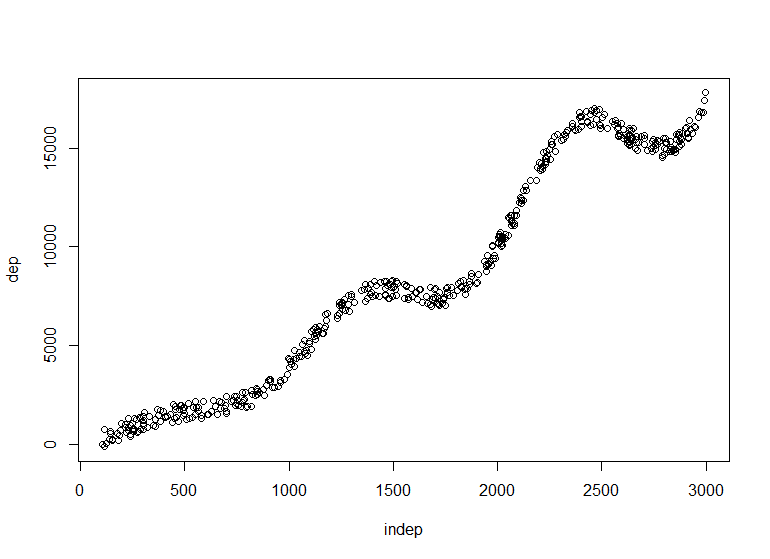
Creamos unos datos aleatorios que serán en una matriz nuestros datos inependientes y como variable dependiente una variable que dibuja una nube de puntos que simula una curva de observaciones. Si realizamos un modelo lineal se ajustará una recta sobre los datos, una red neuronal mejorará los resultados. Y para demostrarlo vamos a emplear el paquete de R monmlp que realiza un perceptrón multicapa y nos puede servir para conocer otras posibilidades de R. Comenzamos con una neurona en la capa oculta de la red:
[sourcecode language=»r»]library(monmlp)
red1 = monmlp.fit(y=dep,x=indep, hidden1=1,n.ensemble=3, bag=T)
prediccion=monmlp.predict(indep,red1)
points(indep,prediccion,col="red")[/sourcecode]
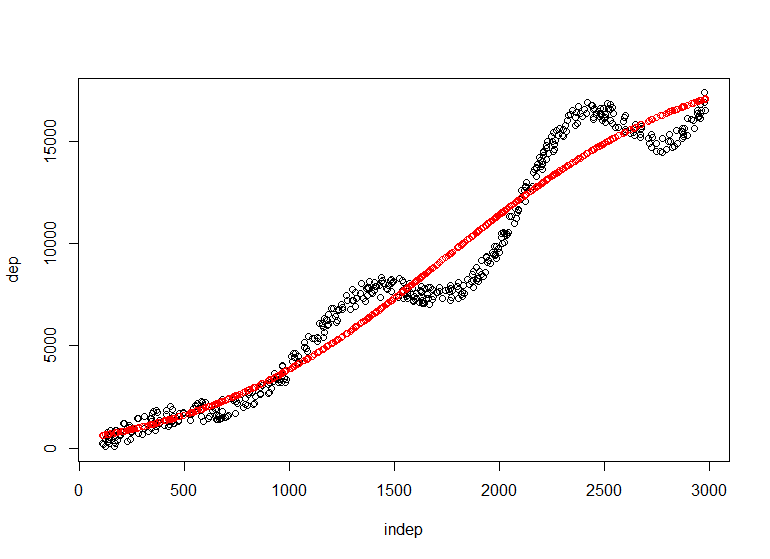
La función monmlp.fit es la que ajusta la red con el perceptrón que necesita en forma de matriz las variables dependientes e independientes, con hidden1 indicamos el número de nodos en la primera capa oculta y mediante bootstrap aggregation (bag=T) podemos evitar el sobreajuste en los 3 ajustes que va a realizar. En el primer caso tenemos una sola neurona y el ajuste mejora sustancialmente al ajuste lineal que podríamos hasta representar gráficamente. Si deseamos añadir complejidad:
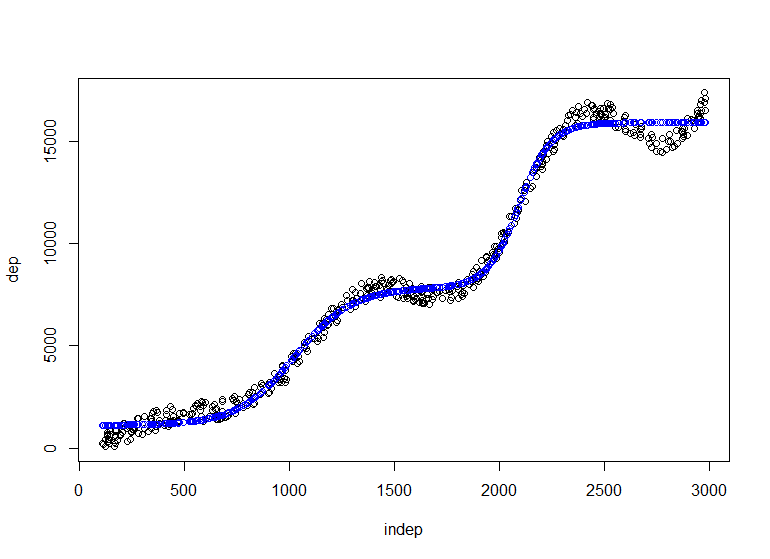
[sourcecode language=»r»]red2 = monmlp.fit(y=dep,x=indep, hidden1=2, n.ensemble=3, bag=T)
prediccion=monmlp.predict(indep,red2)
plot(indep,dep)
points(indep,prediccion,col="blue")[/sourcecode]
[sourcecode language=»r»]red3 = monmlp.fit(y=dep,x=indep, hidden1=3, n.ensemble=3, bag=T)
prediccion=monmlp.predict(indep,red3)
plot(indep,dep)
points(indep,prediccion,col="green")[/sourcecode]
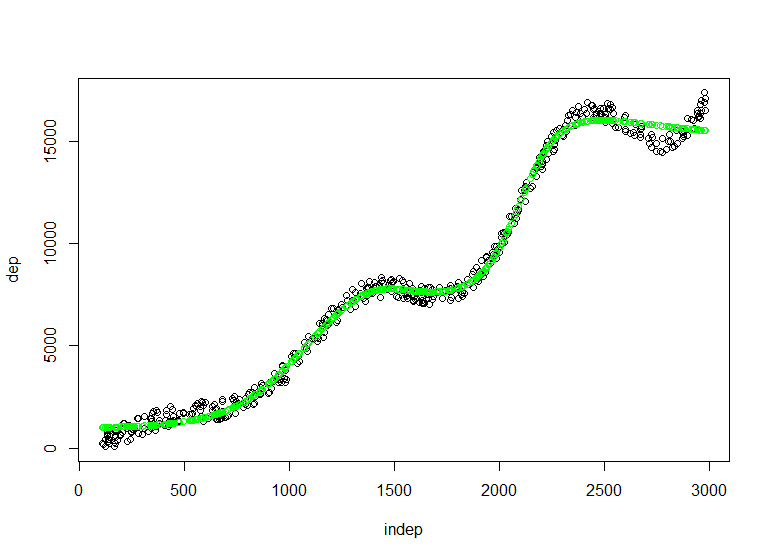
Vemos como añadiendo nodos a nuestra neurona vamos ajustando más a la estructura compleja siempre teniendo presente los problemas que el sobreajuste nos puede causar. Nuestra labor ahora ha de centrarse en como esos nodos, ese reparto de pesos afecta a la estimación y en ese momento esta técnica podrá articular tarifas de riesgo y podremos documentarlas, estaríamos yendo un paso más allá de las técnicas más clásicas. Saludos.
Te deseo mucha suerte en tu desafío aunque no sé yo si el regulador va a seguir las explicaciones que le dés.
Ese es el reto. En realidad, a corto plazo, no tengo muchas esperanzas. Pero todos si todos seguimos haciendo lo mismo…