Vamos a empezar a subir archivos a la BBDD. Evidentemente lo primero que tenemos que hacer es crearnos una BBDD en Postgres. Con el PGAdmin creamos una nueva base de datos, disponemos de varias opciones, en nuestro caso no modificamos ninguna y creamos BD. Ya tenemos una BBDD funcionando y a la hora de conectarnos a ella tendremos que asignarle las propiedades necesarias para su correcto funcionamiento:
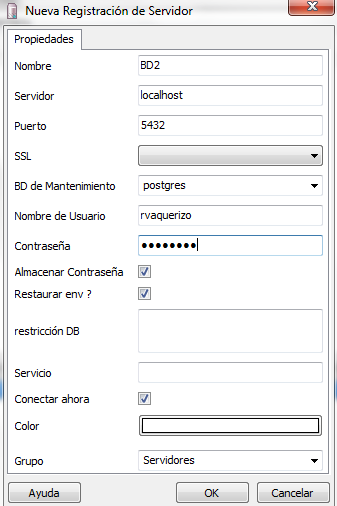
Ya tenemos dispuesta la BBDD y ya podemos empezar a subir tablas. Para ello ya os comenté que usaríamos el Data Integration de Pentaho (antes conocido como Kettle). La intención que tengo al montar este pequeño sistema de información es disponer de una serie de tablas para la realización de modelos estadísticos con R. Podría tener mi equipo lleno de ficheros de texto, de Excel y algún Access por ahí pero es eso lo que pretendo evitar, con esto me garantizo un orden y un correcto acceso a mis tablas. Para comenzar a trabajar quiero subir una tabla del repositorio de datos UCI Quiero seguir trabajando con el paquete e1071 de R y estoy analizando que tablas son las que más se adecúan a mis objetivos, para ello tendré que cargar algunas y comprobar si los datos se adecúan a mis propositos.
Ejecutamos el spoon y comenzamos nuestra tarea. El ejemplo con el que vamos a trabajar le tenéis en este enlace. Nos descargamos los dos ficheros CSV, estoy estudiando como automatizar este paso (sin visual basic) y nuestra tarea será subir estos dos archivos a nuestra BBDD. Para ello lo primero que hacemos es crear una conexión a nuestra BBDD de Postgres. En el Data Integration creamos una nueva transformación, recomiendo guardarla directamente, creamos una conexión a BD y en las propiedades podemos hacer:
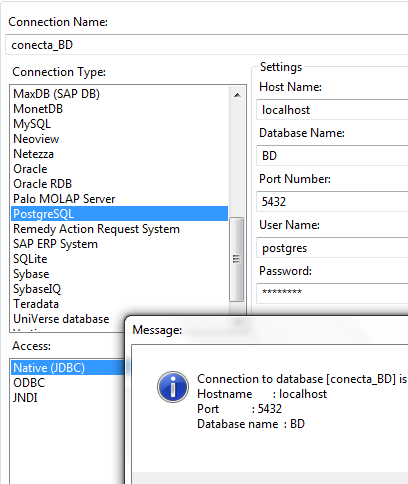
Pocas complicaciones hasta ahora. En el Data Integration añadimos un paso de entrada de CSV y asignamos los formatos a los campos que vamos a leer. Aquí probamos y previsualizamos hasta que tengamos los campos correctamente mapeados. La verdad es que el Pentaho facilita bastante esta tarea. En el caso que tenemos al final obtendríamos algo parecido a esto:
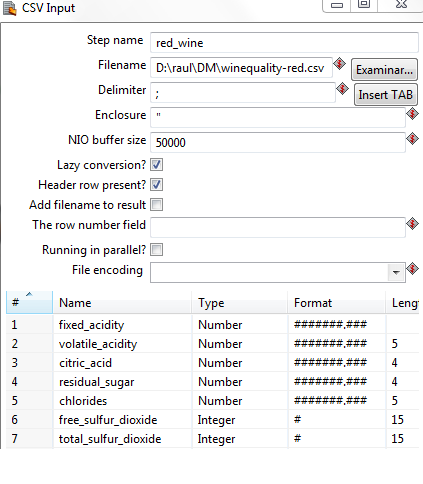
Insisto con el previsualizar. Hasta que se parezca a lo que deseamos obtener. Ahora como salida vamos a emplear un paso SQL File Output. Añadimos un salto entre los dos pasos y ya podemos editar la salida. En este caso podemos hacer:
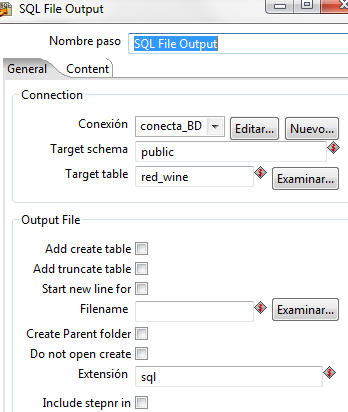
Especificamos el esquema y la tabla de salida. Vemos el SQL que genera y recomiendo analizarlo con cuidado. No siempre Pentaho asigna de forma correcta el tipo de dato para Postgres. En mi caso particular previsualizo los datos y asigno las variables con el create table. Seguro que hay algún paso que nos permita realizar el mapeo de una forma más óptima pero con este método es «directo». Además en el SQL añadimos la sentencia necesaria para subir el fichero de texto a Postgres. Con ello en el SQL podemos poner:
CREATE TABLE "public".red_wine
(
fixed_acidity DOUBLE PRECISION
, volatile_acidity DOUBLE PRECISION
, citric_acid DOUBLE PRECISION
, residual_sugar DOUBLE PRECISION
, chlorides DOUBLE PRECISION
, free_sulfur_dioxide BIGINT
, total_sulfur_dioxide BIGINT
, density DOUBLE PRECISION
, pH DOUBLE PRECISION
, sulphates DOUBLE PRECISION
, alcohol DOUBLE PRECISION
, quality BIGINT
)
;
COPY public.red_wine FROM 'D:\raul\DM\winequality-red.csv' DELIMITER ';' CSV HEADER;
Con COPY podemos subir el CSV al Postgres, especificamos el delimitador y necesitamos el HEADER para indicarle que empiece a leer desde el segundo registro. Con dos pasos en Data Integration podemos subir cualquier fichero a la BBDD, podéis pensar que pinta el Pentaho en todo esto, que podemos hacer el script directamente con SQL. Al final una herramienta de ETL facilita mucho el trabajo. En la próxima entrega conectaremos R con la BBDD. Saludos
Muy buen post. Espero impaciente la siguiente entrega