Sobre la idea de “dumificar” variables he ideado un proceso para agrupar variables cuantitativas en función de una variable respuesta. Los que disponéis de herramientas de análisis más complejas tipo Enterprise Miner o Clementine ya disponéis de algoritmos y funciones que realizan esta útil tarea, además los árboles pueden trabajar con variables continuas. Pero un modelo es bueno si las variables de entrada están bien elegidas y bien construidas y como paso previo al análisis multivariante el análisis univariable es imprescindible. Tramificar una variable continua en función de una variable respuesta no va más allá de un análisis univariante, igualmente podemos tener dependencia lineal entre variables, algo que sólo detectaremos con análisis multivariables. Pero este sencillo algoritmo puede ayudarnos a conocer mejor algunas variables que deseamos introducir en nuestro modelo.
La idea es muy fácil: dispongo de una variable continua y una variable respuesta, divido la variable continua en N variables dicotómicas y mediante una regresión logística determino una respuesta media de cada grupo y si la media de un grupo es muy parecida a la media de otro grupo cercano entonces los uno. Es como un análisis de la varianza en el que medimos que las medias por grupo no sean significativamente distintas de las de otros grupos cercanos. Y este criterio de distinción lo establecemos nosotros con unos criterios de corte basados en la diferencia relativa con la media del grupo más cercano esté dentro de un rango.
El proceso haría un bucle de la idea anterior con tantas iteraciones como deseemos, e iría agrupando la variable en función del peso de la variable respuesta dentro de cada grupo. Muy sencillo y vais a entenderlo con el ejemplo de SAS. Como siempre parto de un dataset aleatorio con un importe y una variable respuesta:
*DATASET ALEATORIO;
data uno;
do i=1 to 20000;
importe=ranuni(0)*10000;
if rand(«uniform»)<.04 then resp=1;
else resp=0;
if resp=0 and 200<importe0.2);
if resp=0 and 8000<importe0.2);
output;
end;
run;
Es evidente que la variable respuesta está inflada para los importes entre 200 y 400 y para los importes entre 8000 y 9000. A continuación os planteo la macro que tramifica y analizaremos sus resultados:
%macro numobs(ds,mv);
%global &mv.;
data _null_;
datossid=open(«&ds.»);
no=attrn(datossid,’nobs’);
call symput («&mv.»,compress(no));
datossid=close(datossid);
run;
%mend;
%macro rangea (datos,cuantitativa,respuesta);%numobs(&datos.,obs);
*CORTES QUE GENERAN GRUPOS PODEMOS SER MÁS LAXOS O NO;
%let cortes=0.8<=relativa<=1.2 ;
*ESPECIFICAMOS EL NÚMERO Y EL TAMAÑO DE LOS GRUPOS INICIALES;
%let numero_de_grupos=30;
*ORDENAMOS POR LA VARIABLE QUE DESEAMOS CATEGORIZAR;
proc sort data=&datos.; by &cuantitativa.; run;
*CREAMOS 30 GRUPOS INICIALES;
data &datos.;
set &datos.;
*CREAMOS N GRUPOS;
rango=ceil((_n_/&obs.)*&numero_de_grupos.);
run;
*CREAMOS VARIABLES DUMMY;
data instruccion;
do i=1 to &numero_de_grupos.;
instruccion=»GR_»||compress(put(i,3.))||»=0; IF RANGO=»||put(i,3.)||» THEN GR_»||compress(put(i,3.))||»=1″;
output;
end;
run;
proc sql noprint ;
select instruccion into:instr separated by «;»
from instruccion;
quit;
proc delete data=instruccion;
data &datos.;
set &datos.;
&instr.;
run;
*BUCLE QUE AGRUPA LAS DICOTOMICAS EN FUNCION DE LOGISTICA;
%let ejecuta=1;
*PUEDES MODIFICAR EL NUMERO DE ITERACCIONES;
%do i=1 %to 10;
%if &i.=1 %then %do; %let fin_variables=GR_30;%end;
%if &ejecuta. %then %do;
proc logistic data = &datos. noprint descending
outest = paso&i. ;
model &respuesta.=gr_1 — &fin_variables.;
run;
proc transpose data=paso&i. out=paso&i. (where=(index(_name_,»GR»)>0) drop=_label_);
quit;
*ESTA PARTE GENERA LOS NUEVOS RANGOS Y LAS NUEVAS DICOTOMICAS;
data paso&i.;
set paso&i. end=ultimo;
*PROBLEMA DE PESO 0;
&respuesta.=&respuesta.+0.0000000001;
retain rango 1;
anterior=lag(&respuesta.);
if anterior=. then anterior=&respuesta.;
relativa=anterior/&respuesta.;
junta=0;
if &cortes. then junta=1;
if junta=0 then rango=rango+1;
rango_ant = compress(_name_,»GR_»);
instruccion=»GR_»||compress(put(rango,3.))||»=0; IF RANGO=»||rango_ant||» THEN DO; GR_»||compress(put(rango,3.))||»=1; RANGO=»||rango||»;END;»;
if ultimo then call symput(‘fin_variables’,»GR_»||compress(put(rango,3.)));
run;
proc sql noprint ;
select instruccion into:instr separated by «;»
from paso&i.;
quit;
data &datos.;
set &datos. (drop=gr:);
&instr.;
run;
*SI YA NO HAY MODIFICACIONES NO TIENE SENTIDO SEGUIR CON EL PROCESO;
proc sql noprint;
select max(junta) into:ejecuta
from paso&i.;
quit;
proc delete data=paso&i.; run;
%end;
%end;
data &datos.;
set &datos.;
drop gr:;
run;
%mend;
%rangea(uno,importe,resp);
Larga y compleja así a primera vista, pero muy sencilla de entender si se realizan ejecuciones y se comprueba su funcionamiento, recomiendo comentar el último PROC DELETE para ver como evoluciona cada paso de la iteración. Partimos de 30 grupos (suficiente de inicio) y realizamos una regresión logística de las 30 variables generadas, creamos un dataset en el que vemos si los grupos tienen similar peso. Vemos como sería la primera iteración:
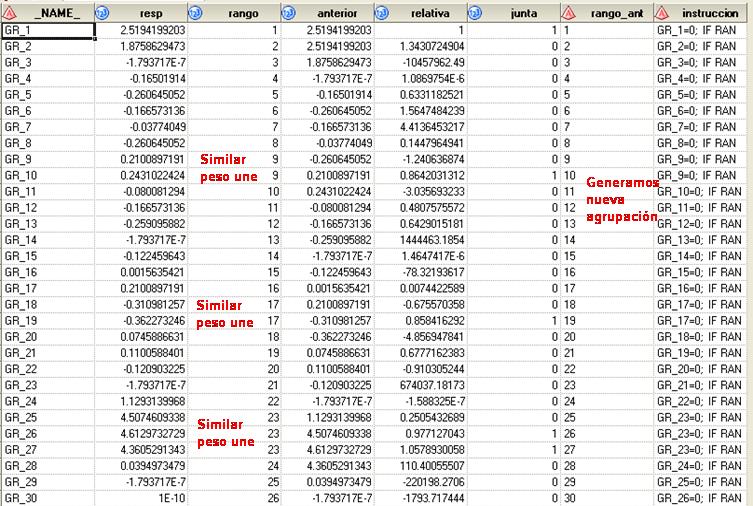
Pesos dentro de nuestro criterio de corte (%let cortes=0.8<=relativa<=1.2) se unen gracias a que creamos una instrucción automática con PROC SQL. Así hasta 10 veces se ejecuta y al final el dataset de entrada de la macro tiene un campo rango que nos ha trameado la variable cuantiva en función de la respuesta. Si analizamos su comportamiento:
proc sql;
select rango, min(importe) as min_importe, max(importe) as max_importe,
COUNT(*) AS OBS,sum(resp), sum(resp)/count(*) as peso
from uno
group by 1;
quit;
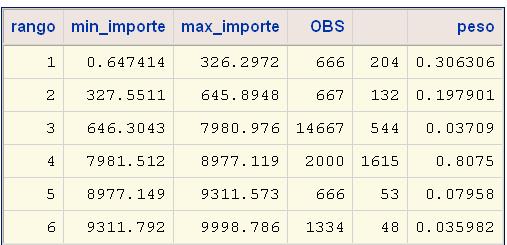
Ha encontrado perfectamente el tramo entre 8000 y 9000 y un poco peor con el tramo de 200 a 400 probablemente porque tiene menos registros. Podría hacer más uniones, pero si hace un análisis exploratorio bastante interesante. Queda pendiente estudiar que pasaría con este proceso si nos encontramos con valores muy frecuentes, por ejemplo el valor 0. Próximas entregas y como siempre dudas, sugerencias u ofertas de trabajo que me permitan ver a mis hijos desde las 4 de la tarde rvaquerizo@analisisydecision.es
Hola! acabo de descubrir tu blog y es muy muy muy interesante! Te felicito!
estoy probando este método para codificar una contínua en función de una dependiente, que me resulta muy útil, pero no acabo de ver claros los resultados que me da.
a simple vista, viendo el gráfico inicial de como varia var con mi numérica, haría intervalos muy diferentes (lástima que no pueda compartir los dos gráficos). ¿A qué crees que se debe?
Hola,
Estoy aprendiendo sas y tus trucos son muy utiles y facil de aplicar
Estoy tratando de ejecutar el codigo pero no funciona
Error: Integration technologies failed to submit the code. [Error] Failed to transcode …
Por que no funciona?
Gracias por tu ayuda,
Un saludo
Hola, ¿en qué paso te da? Es una entrada muy antigua, ya no soy usuario de SAS y no puedo replicar el proceso.
Hola…
Gracias por contestarme…muy gentil de tu parte.
La verdad, me da problemas desde el comienzo… es que estoy aprendiendo sas.
(He seguido varios de tus trucos…y son muy utiles..se agradece)
Un saludo,
Gladys