Creo que cualquier persona con conocimientos de estadística cada vez que juega a un juego de probabilidades (¿el 99.9% de los juegos existentes?) lo primero que piensa, por deformación profesional, es en cómo inferir un patrón ganador para optimizar sus movimientos.
Por ejemplo, en el juego de Los colonos de Catán donde se juega con dos dados, nunca elegiría situar mi poblado en la celda 2 o 12 (con probabilidades de 1/36) estando libres la 6 o la 8 (probabilidades de 5/36). De hecho, el 7 que es la suma más probable (6/36) está reservada para mover el ladrón y así equilibrar las posiciones del tablero.
Dicho lo anterior, la primera vez que jugué al Wordle busqué qué palabras optimizarían la probabilidad de acierto. Al no encontrar nada (toda la literatura al respecto, aún en castellano, hacen mención a palabras en inglés), por mi aprendizaje humano inferí que las palabras con muchas vocales serían buenas opciones.
Adicionalmente, por mi condición de actuario, tengo la necesidad innata de jugar la segunda palabra sin repetir ninguna letra de la palabra anterior. Esto es lo que se conoce como pagar una prima de riesgo, en este caso perder una oportunidad de seis a cambio de obtener mayor información o seguridad. De hecho, sin que nos demos cuenta , las primas de riesgo están en muchas decisiones que tomamos, no sólo en el mundo asegurador, pero eso daría para otra entrada.
Por lo tanto, como además de actuario de profesión soy hacker de afición, me he descargado la base de datos de mi viejo amigo Jorge (¡ya enredábamos con python hace 14 años !, aquí podéis consultar su araña en python para obtener la información de la página de la RAE), y he escrito el siguiente script para hallar que dos palabras optimizarían mi probabilidad de ganar al tercer intento.
Explicación del script
La idea es encontrar las letras que, al igual que las casillas del Colonos de Catán, maximen mi probabilidad de éxito. Para ello, importo las librerías que voy a utilizar y el diccionario de palabras de la RAE (646.616 palabras). A continuación, selecciono aquellas palabras con longitud igual a 5 y quito las palabras duplicadas ya que al eliminar las tildes se duplicaban palabras (9.458 palabras). Creo la gráfica de frecuencia de letras usando mi diccionario de palabras válidas:
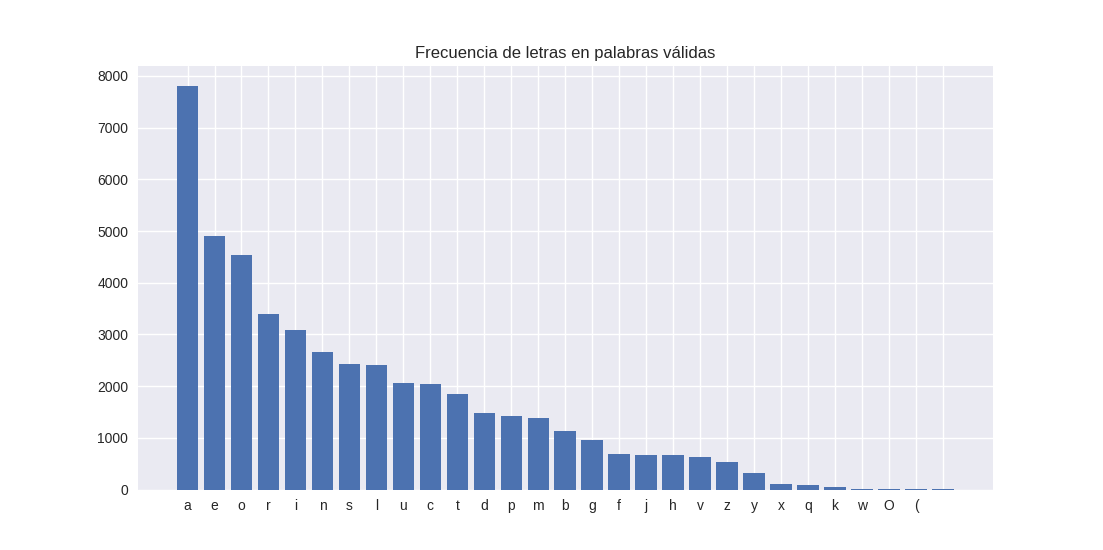
Por tanto, mi orden de vocales será: A-E-O-I-U y de consonantes: R-N-S-L-C-T-D-P-M-B-G-F-J-H-V-Z-Y-X-Q-K-W.
Con el dataframe de palabras válidas, creo otro de palabras válidas con letras únicas que no se repitan dentro de la palabra (5.456 palabras) para definir una función (crea_wordle()) que cree con 2 vocales y 3 consonantes la combinación de letras que se formen, sin reemplazamiento, mis dos palabras iniciales: ACTOR y SENIL.
Sin embargo, ya que existe intervención humana a la hora de seleccionar la palabra por parte de Wordle, el diccionario de la RAE puede que no sea la fuente más optima (ya que muchas de las palabras no son las más utilizadas en el vocabulario común). Así que para aproximarme algo más a una muestra de palabras más utilizadas, he repetido el mismo ejercicio usando las palabras que aparecen en el Quijote y así obtener otra distribución de frecuencias. Según Cervantes, el orden de las vocales sería: A-O-E-I-U y de las consonantes: S-R-L-N-T-C-D-M-P-B-V-G-H-J-F-Y-Z-Q-X. Si nos fijamos, en ambas fuentes encontramos las mismas primeras 10 letras con cierta variación, pero son las mismas.
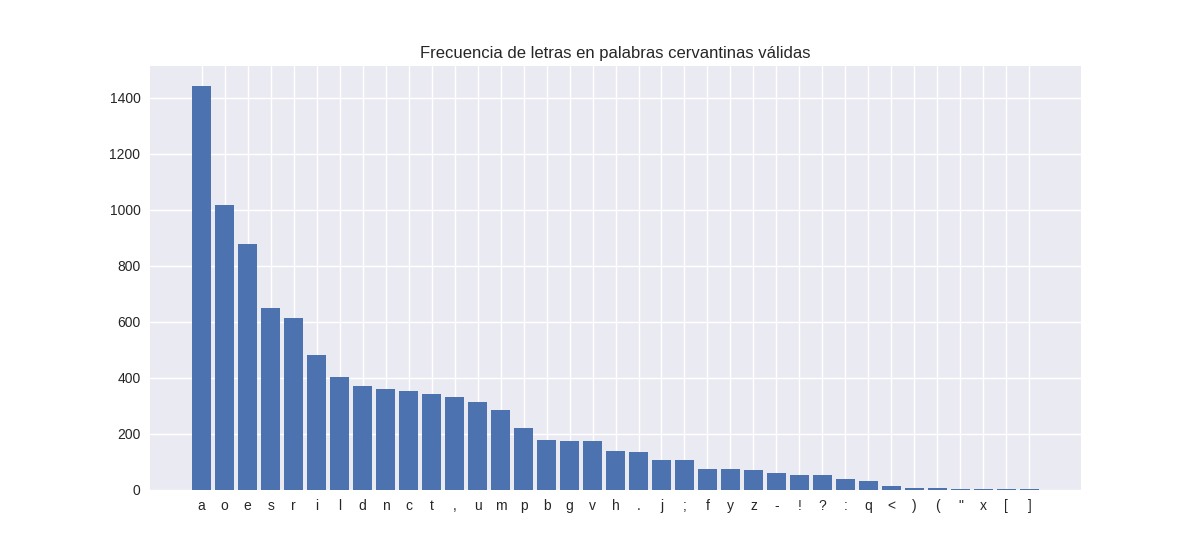
Es decir, podemos decir que tanto la RAE como el Quijote coinciden a la hora de definir mi set de letras a utilizar para obtener mis dos palabras de prueba, si bien Cervantes hubiese elegido, si jugase al Wordle, LICOR y ANTES. ¿Cuales palabras son mejor para empezar? Pues dependiendo del nivel de literato o literata con que te hayas levantado, tanto ACTOR SENIL como LICOR ANTES son buenas candidatas.
¿Pero no sería mejor tener en cuenta el orden de aparición de las palabras para optimizar los verdes en las primeras rondas? Pues es cierto que fijar una posición (el verde) es mejor que conocer la existencia dentro de la palabra (el amarillo dorado), pero hay que tener en cuenta que también jugará a nuestro favor el sesgo que tienen las palabras (por ejemplo de finalizar en A o en O) a la hora de elegir las posibles palabras candidatas. Para responder esta pregunta, la mejor opción sería aplicar un enfoque de aprendizaje automático que me comprometo a realizarlo una vez tenga un dataframe con 100 casos de control (en unos meses al ritmo de Wordle).
Una vez llegamos a este punto, pongamos a prueba nuestro script. El funcionamiento es fácil: empezar con ACTOR-SENIL y consultar en la RAE (con la misma función crea_wordle) las posibles palabras ganadoras teniendo cuenta la información recibida. En el caso de que tengamos muchas palabras candidatas, podemos limitar la búsqueda a las palabras que aparecen en el Quijote.
Ejemplo 1

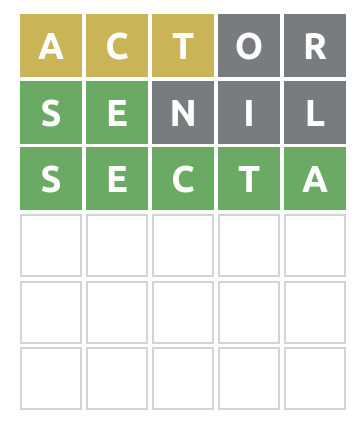
Este caso es demasiado fácil ya que, con la información recibida, las posibles palabras dentro de la RAE se limita a una:
posibles = crea_wordle('actse', df_validas)
ganadora = list(filter(lambda x:(x[:2]=='se'), posibles.Palabras_de_5))
ganadora = list(filter(lambda x:('a' and 'c' and 't' in x), ganadora))
print(ganadora)
[‘secta’]
Ejemplo 2

Aquí, tengo que hacer uso del resto de letras dentro de mi función crea_wordle() para obtener las siguientes palabras candidatas:
posibles = crea_wordle('anrudmpbvghjfyzqx', df_validas)
ganadora = list(filter(lambda x:(x[2]=='n'), posibles.Palabras_de_5))
ganadora = list(filter(lambda x:(x[4]=='r'), ganadora))
ganadora = list(filter(lambda x:('a' in x), ganadora))
print(ganadora)
[‘aunar’, ‘banar’, ‘danar’, ‘dunar’, ‘fanar’, ‘funar’, ‘ganar’, ‘manar’, ‘punar’, ‘runar’]
Al existir múltiples opciones (aunque una clara candidata), decido limitar la búsqueda a la base de datos del Quijote, que es lo más parecido a lo que haría nuestro cerebro, obteniendo sólo una palabra posible:
posibles = crea_wordle('anrudmpbvghjfyzqx', df_quijote_validas)
ganadora = list(filter(lambda x:(x[2]=='n'), posibles.Palabras_de_5))
ganadora = list(filter(lambda x:(x[4]=='r'), ganadora))
ganadora = list(filter(lambda x:('a' in x), ganadora))
print(ganadora)
[‘ganar’]

En conclusión, y a la espera de verificar como influiría el posicionamiento, podemos decir que ACTOR y SENIL serían las mejores palabras para comenzar en el Wordle. LICOR y ANTES si hubiésemos nacido en el siglo XVII.