Revisión de los gráficos más habituales que realizaremos en labores descriptivas de variables con Python, se emplea seaborn para ilustrar estos ejemplos. El tipo de gráfico dependerá del tipo de variable que deseamos describir e incluso del número de variables que deseamos describir Como aproximación inicial describiremos variables cuantitativas o variables cualitativas análisis univariables o análisis bivariables. Se trabaja con el conjunto de datos iris:
import seaborn as sns
import pandas as pd
import numpy as np
import io
import requests
url='https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv'
s=requests.get(url).content
df=pd.read_csv(io.StringIO(s.decode('utf-8')))
df.head()
Análisis univariables
Variables cuantitativas
Cuando describimos variables cuantitativas lo principal es conocer su forma, sobre que valores se hayan los datos y como son de dispersos y para ello el gráfico estrella es el histograma:
sns.histplot(data=df, x="sepal_width")
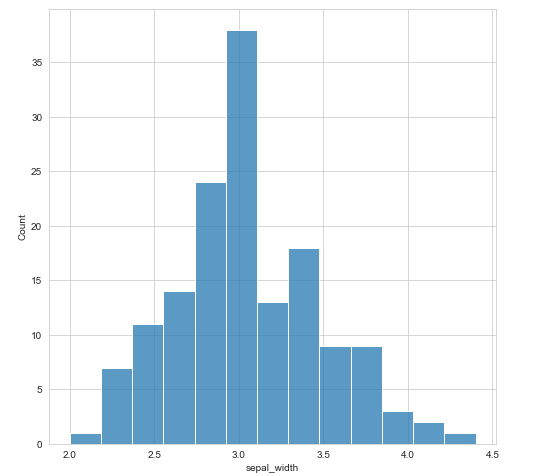
Si queremos ver la distribución como una línea continua disponemos de los gráficos de densidad:
sns.kdeplot(df['sepal_width'], bw=0.5)
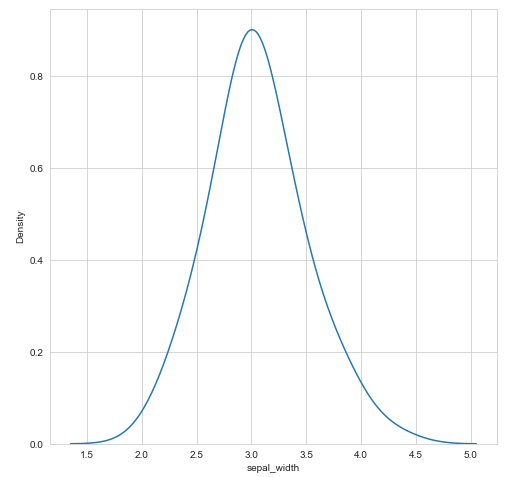
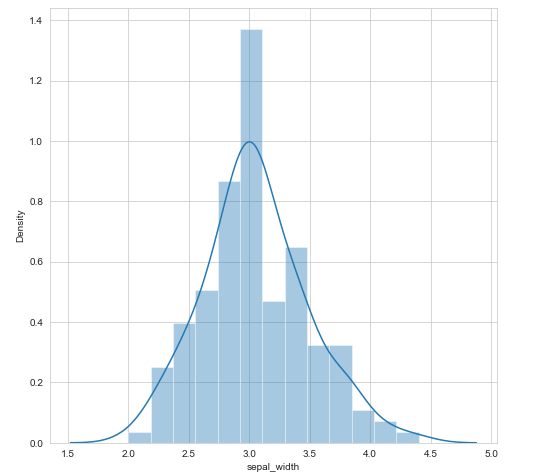
Como sugerencia unir ambos gráficos con distplot:
sns.distplot(df['sepal_width'])
El otro gráfico que destacaría sería el gráfico de cajas y bigotes que llamaremos boxplot y que es así de sencillo con seaborn:
sns.boxplot(x="sepal_length", data=df)
Este gráfico nos dice mucho de una variable, esa caja nos indica donde están el 75% que es lo que definimos como rango intercuartílico, hay una línea que nos indica la mediana y esos «bigotes» nos dan una medida de lo dispersos que se encuentran los datos, e incluso si hay observaciones que están 1,5 veces por encima del rango intercuartílico las da más importancia marcándolas con puntos y que se pueden denominar datos extremos.
Variables cualitativas
Para describir variables cualitativas el gráfico más habitual es el gráfico de barras donde contamos observaciones, en seaborn tenemos countplot:
sns.countplot(x='species', data=df)

Sin embargo, se sugiere que este tipo de gráficos se haga después de realizar una tabla de agregación, en este caso con pandas, los tiempos de ejecución siempre son menores:
agr = df[['sepal_length','species']].groupby('species').count()
agr = agr.reset_index()
sns.barplot(x='species', y='sepal_length', data=agr)

Con seaborn no se pueden hacer gráficos de tarta, así que no describiremos variables cualitativas de ese modo.
Análisis bivariable
Disponemos de los gráficos básicos para describir una variable, pero habitualmente necesitaremos describir una variable en función de otra y así tenemos gráficos bivariables con las posibles combinaciones entre los tipos de las variables a describir.
Dos variables cuantitativas
En este caso tenemos el el habitual gráfico de puntos.
sns.scatterplot(data=df, x="sepal_length", y="sepal_width")
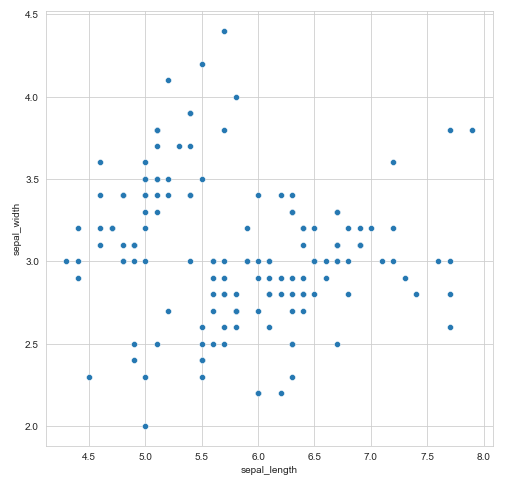
Al que podemos añadir una variable cualitativa para identificar segmentos:
sns.scatterplot(data=df, x="sepal_length", y="sepal_width", hue="species")
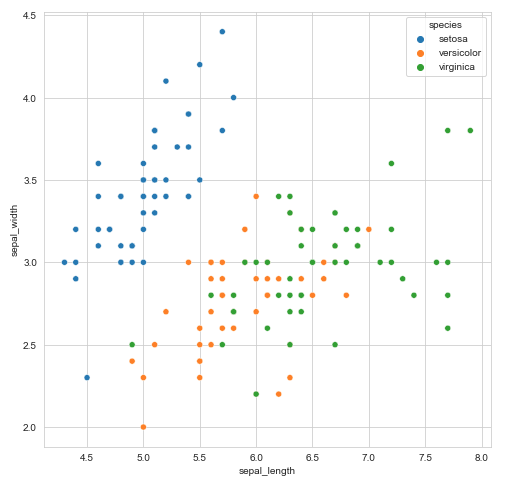
Se aprecia como hue sirve para generar ese segmento. En otros gráficos que hemos trabajado, como los gráficos de densidades, en vez de hue directamente se trabaja con data frames separados, como en el ejemplo siguiente, que compara los gráficos de densidades de una variable en función de otra cuantitativa:
df1 = df[df['species']=="setosa"] df2 = df[df['species']=="versicolor"] sns.kdeplot(df1['sepal_length'], bw=0.5) sns.kdeplot(df2['sepal_length'], bw=0.5)

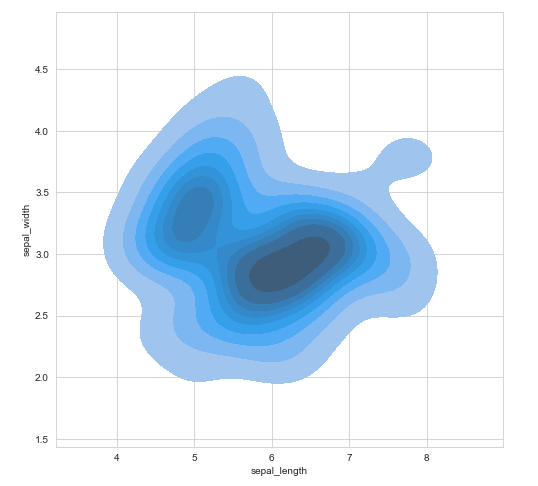
También se pueden realizar gráficos de densidades bivariables:
sns.kdeplot(df['sepal_length'],df['sepal_width'],shade=True)
Dos variables cualitativas
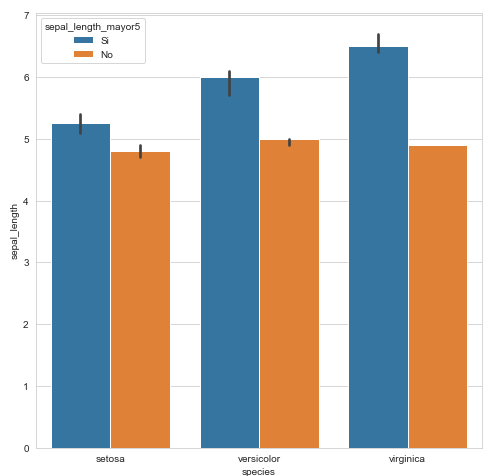
En este caso es necesario emplear otras posibilidades de los gráficos de barras como añadir una nueva barra:
df['sepal_length_mayor5'] = np.where(df['sepal_length'] > 5,"Si", "No") sns.barplot(x='species', y='sepal_length', hue = 'sepal_length_mayor5', data=df, estimator= np.median)
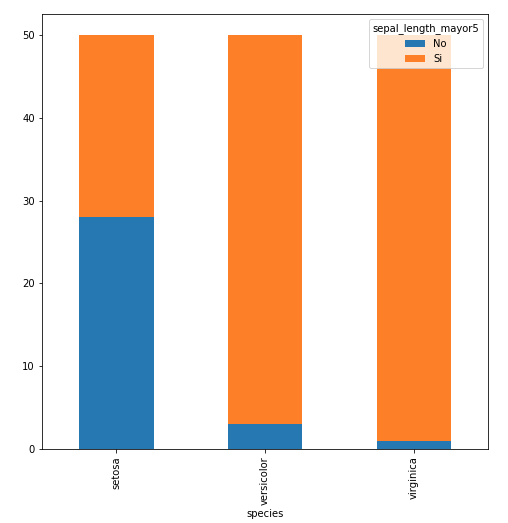
Para columnas agrupadas no se recomienda el uso de seaborn, se complica el código. Pero se puede realizar con Pandas:
agr = df.groupby(['species', 'sepal_length_mayor5']).size().reset_index().pivot(columns='sepal_length_mayor5', index='species', values=0) agr.plot(kind='bar', stacked=True)
Una variable cuantitativa frente a una variable cualitativa
Por último una mezcla entre ambos tipos de variables, con anterioridad se vio algún ejemplo, pero son imprescindibles los gráficos de densidades frente a variables cualitativas:
sns.displot(data=df, x="sepal_length", hue="species", kind="kde")
sns.boxplot(x="sepal_length", y='species', data=df)
Una entrada sencilla que sirve para ilustrar en pocas líneas el 80% de los gráficos que realiza un científico de datos en su vida profesional. Se ha querido emplear seaborn por tener un factor diferenciador, esta librería destaca en sus gráficos de densidades, hay otros análisis donde matplotlib es más habitual.