
Hace años ya tuvimos nubes de palabras en el blog y ya era hora de ir actualizando algunas cosas. Y además quería aprovechar y presentaros un paquete de R que nos permite consultar la API del Europe PMC. Para quien no sepa que es el Europe PMC podemos decir que es un un buscador de documentos y artículos científicos (que ahora todo el mundo molón llama papers) y que tiene una API desde la que podemos acceder desde R mediante el paquete europepmc.
Obtener datos de la API de Europe PMC con R
El primer paso para trabajar con la librería de R europepmc sería obtener el número de artículos publicados con el topic «Autism» en su descripción, para ello podemos hacer:
#install.packages("europepmc")
library(dplyr)
library(ggplot2)
library(europepmc)
autismo <- epmc_hits_trend("Autism", period = 2000:2019, synonym = TRUE)
autismo
ggplot(autismo, aes(year, query_hits)) +
geom_line() +
xlab("Año de Publicación") +
ylab("Articulos publicados sobre Autismo")
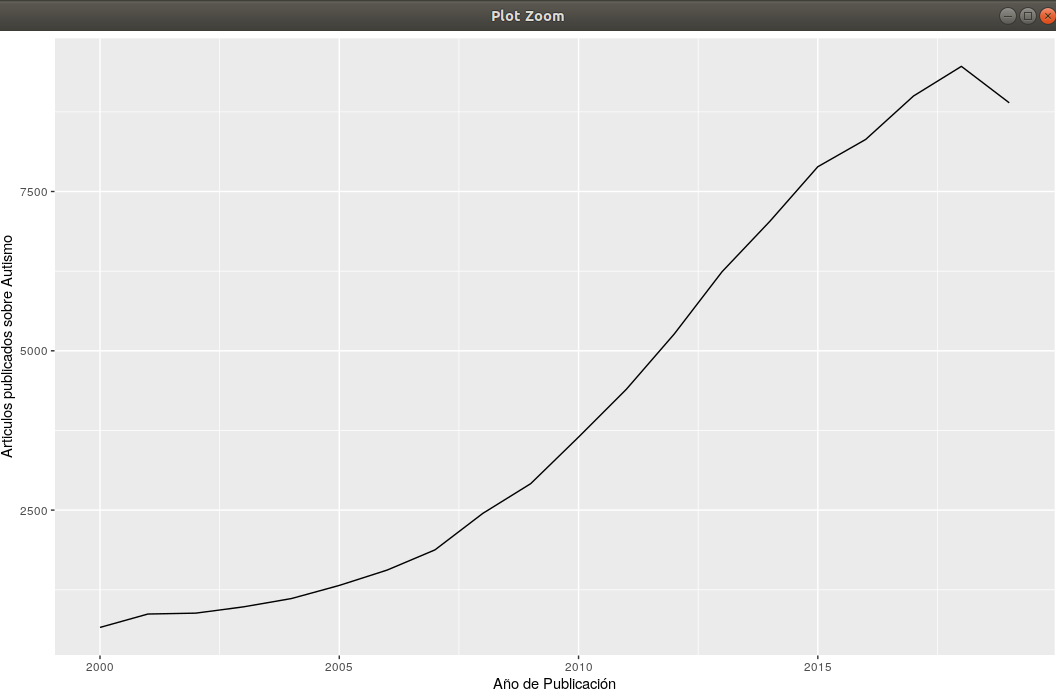
La función del paquete de R europepmc epmc_hits_trend obtiene de un periodo dado el número de artículos y el número de artículos de un determinado tópico. Como vemos se está incrementando casi exponencialmente el número de artículos dedicados al Autismo en los últimos años, no es una tendencia particular, se está incrementando el número de papers (asco de término pero que tiene que aparecer para las búsquedas), estamos ante la «burbuja de los papers» ya que da mas notoriedad hacer mucho que hacer bien, ya se lo leerá una inteligencia artificial, en fin que me disperso. Pero la función que puede resultarnos más interesante es epmc_search que crea un data frame con las búsquedas de los artículos con su ISBN, fechas de referencia, autores,… nos va a servir para obtener unas nubes de palabras sobre los escritos acerca del autismo:
autismo <- epmc_search("Autism", limit=10000)
library(tm)
#Create a vector containing only the text
text <- autismo$title
# Create a corpus
docs <- Corpus(VectorSource(text))
docs <- docs %>%
tm_map(removeNumbers) %>%
tm_map(removePunctuation) %>%
tm_map(stripWhitespace)
docs <- tm_map(docs, content_transformer(tolower))
docs <- tm_map(docs, removeWords, stopwords("english"))
dtm <- TermDocumentMatrix(docs)
matrix <- as.matrix(dtm)
words <- sort(rowSums(matrix),decreasing=TRUE)
df <- data.frame(word = names(words),freq=words)
epmc_search por defecto se descarga 100 entradas con limit establecemos el número, en este caso disponemos de 96.000 entradas (nunca poner 96k entradas) pero seleccionamos 10.000 posteriormente realiazamos una preparación del texto que deseamos analizar y graficar, esta preparación está sacada de este enlace de Towards Data Science tampoco es muy compleja y creo que se puede extrapolar al español, el trabajo se realiza con la librería tm, en el blog tenéis el uso de expresiones regulares para esta tarea. Al final nos queda un data frame con palabra y frecuencia que podemos emplear para crear las nubes de palabras.
Nubes de palabras con R y la librería wordcloud
El primer paso para crear nubes de palabras con R será la instalación de los paquetes:
install.packages("wordcloud")
require(devtools)
devtools::install_github("lchiffon/wordcloud2")
He querido hacer este inciso (redundante) porque he tenido problemas con wordcloud2 que se han solventado tras instalar directamente desde github la librería. Una vez las tenemos instaladas la sintaxis no ha variado mucho para wordcloud:
library(wordcloud)
library(RColorBrewer)
library(wordcloud2)
wordcloud(words = dfword, freq = dffreq, min.freq = 3,
max.words=200, random.order=FALSE,
colors=brewer.pal(10, "Spectral"))

Nubes de palabras con R y la librería wordcloud2
La novedad de la entrada la tenemos con wordcloud2 que nos ofrece más posibilidades:
library(wordcloud2) wordcloud2(df, shape="start", minSize = 1) + WCtheme(3)

Una de las delicadezas que nos brinda wordcloud2 es que podéis tener problemas a la hora de visualizar los resultados, si esto ocurre en el visor de gráficos arriba a la derecha tenéis un botón que es show in new window, le dais y debería abrirse el navegador, si sigue sin verse nada dad a actualizar y no seáis impacientes, los resultados aparecerán y son mejores.
Si queremos hacer nubes de palabras en una palabra tenemos la función letterCloud:
dffreq <- sqrt(dffreq)
letterCloud(df,"AUTISM")

Recomiendo hacer la raíz cuadrada de la frecuencia de las palabras para que el resultado quede mejor ya que uno de los términos puede tener mucho peso. Por último si queréis añadir vuestra propia imagen para realizar nubes de palabras lo que tenéis que hacer es disponer de la imagen, en este caso yo quería un corazón y me fui a wikipedia y obtuve la imagen de un corazón. Con el PhotoGIMP me costó una peonada poner el corazón en negro, no sé si era necesario hacerlo pero lo hice y una vez hecho guardé la imagen como png y referencio a esa imagen con el parámetro filePath de wordcloud2 para obtener el resultado con el que inicio la entrada:
{kind=link}
wordcloud2(df, shape="start", minSize = 1) + WCtheme(3) corazon = "/home/ruli/Descargas/corazon.png" wordcloud2(df, figPath = corazon)
Buen gráfico final, ahora espero que alguien recoja el guante y demuestre que estamos ante una burbuja de papers, ya sabéis como obtener datos y como ponerlos bonitos.