En este capítulo del curso de R vamos a comenza a estudiar el análisis de regresión lineal. Los modelos de regresión lineal son modelos probabilísticos basados en una función lineal, nuestro objetivo es expresar una variable dependiente en función otro conjunto de variables. Los pasos básicos a seguir en el estudio de un modelo lineal son:
1. Escribir el modelo matemático con todas sus hipótesis.
2. Estimación de los parámetros del modelo.
3. Inferencias sobre los parámetros.
4. Diagnóstico del modelo.
No nos vamos a detener en todos los pasos puesto que si lo hiciéramos el capítulo quedaría demasiado extenso. Vamos a analizar las posibilidades que tenemos con R y para que nos pueden servir los modelos lineales.
La función que realiza los modelos lineales en R es lm «lineal model». Pero esta función no nos ofrece ninguna salida por pantalla si no que nos crea un objeto, o mejor dicho, nosotros creamos un objeto que va a ser un modelo de regresión lineal. Este objeto puede ser referenciado por cualquier función para realizar un análisis de la varianza, un modelo autoregresivo,… La función lm tiene la siguiente sintaxis:
lm(formula, data, subset, weights, method = "qr", model = TRUE, x = FALSE, y = FALSE, qr = TRUE, contrasts = NULL, ...)
En formula ponemos el modelo expresado: y ~ x1+x2+…+xn
En data especificamos el data frame que contiene las variables del modelo en el caso de que trabajemos con un data frame.
En subset especificamos un subconjunto de observaciones para validar posteriormente el modelo.
En weights especificamos los pesos, útil si hacemos mínimos cuadrados ponderados.
Con method especificamos el método. No entramos puesto que con el módulo base sólo es posible obtener el modelo por mínimos cuadrados.
En model con TRUE decimos a R que ha de guardarse en el objeto, la matriz del modelo, la frame,…
En contrast podemos especificar objetos con los que realizar contrastes sobre los parámetros.
Tiene múltiples opciones, para ver cuales son empleamos la ayuda (?lm) y vemos la documentación R sobre el procedimiento lm. En este caso para conocer mejor su funcionamiento comenzamos a trabajar con ejemplos:
Ejemplo 9.1:
El tiempo que tarda un sistema informático en red en ejecutar una instrucción depende del número de usuarios conectados a él. Si no hay usuarios el tiempo es 0. Tenemos los siguientes datos:
| Nº usuarios |
Tiempo de ejecución |
| 10 |
1 |
| 15 |
1.2 |
| 20 |
2 |
| 20 |
2.1 |
| 25 |
2.2 |
| 30 |
2 |
| 30 |
1.9 |
Se pretende ajustar un modelo lineal sin término independiente, construir la tabla ANOVA y comparar el modelo con el de término independiente. Veamos las intrucciones en R:
> tiempo<-c(1,1.2,2,2.1,2.2,2,1.9)
> usuarios<-c(10,15,20,20,25,30,30)
> ejemplo9.1<-lm(tiempo~usuarios-1) #El modelo se crea en un objeto
> summary(ejemplo9.1)Call:
lm(formula = tiempo ~ usuarios - 1)
Residuals:
Min 1Q Median 3Q Max
-0.4831 -0.1873 0.2056 0.3127 0.5113Coefficients:
Estimate Std. Error t value Pr(>|t|)
usuarios 0.079437 0.006496 12.23 1.82e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3871 on 6 degrees of freedom
Multiple R-squared: 0.9614, Adjusted R-squared: 0.955
F-statistic: 149.5 on 1 and 6 DF, p-value: 1.821e-05
Los modelos se escriben de la forma dependiente~indepentiente1+independiente2+…+independienten con -1 le indicamos a R que es un modelo sin término independiente. En este caso el modelo resultante sería: tiempo de ejecución=0.0794usuarios, también decir que es un excelente modelo lineal ya que el Multiple R-Squared: 0.9614 (coeficiente de determinación ajustado) es bastante próximo a 1 (el mejor valor posible). Para construir la tabla del análisis de la varianza hemos de emplear la instrucción anova(objeto). El objeto lógicamente va a ser nuestro modelo lineal:
> an.varianza<-anova(ejemplo9.1)
> summary(an.varianza)
Df Sum Sq Mean Sq F value Pr(>F)
Min. :1.00 Min. : 0.8989 Min. : 0.1498 Min. :149.5 Min. :1.821e-05
1st Qu.:2.25 1st Qu.: 6.2744 1st Qu.: 5.7126 1st Qu.:149.5 1st Qu.:1.821e-05
Median :3.50 Median :11.6500 Median :11.2755 Median :149.5 Median :1.821e-05
Mean :3.50 Mean :11.6500 Mean :11.2755 Mean :149.5 Mean :1.821e-05
3rd Qu.:4.75 3rd Qu.:17.0256 3rd Qu.:16.8383 3rd Qu.:149.5 3rd Qu.:1.821e-05
Max. :6.00 Max. :22.4011 Max. :22.4011 Max. :149.5 Max. :1.821e-05
NA's : 1.0 NA's :1.000e+00
Ejemplo 9.2:
Nos han enviado por correo electrónico un archivo de texto que contiene las notas de la asignatura de estadística de un centro universitario. Nos piden que hagamos un modelo para predecir las notas finales a partir de las notas de los exámenes previos, el test y la puntuación del laboratorio. Pincha aquí para ver el archivo. La descripción del archivo viene recogida en la siguiente tabla:
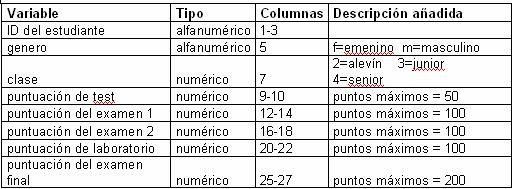
El primer paso que debemos dar es leer el fichero de texto para transformarlo en un objeto de R para ello empleamos la función read.table:
> #Si deseamos leer los datos directamente de la web:
> datos<-read.table(url("https://es.geocities.com/r_vaquerizo/Conjuntos_datos/GRADES.TXT"))
Error en open.connection(file, "r") : no fue posible abrir la conexión
Además: Warning message:
In open.connection(file, "r") : unable to resolve 'es.geocities.com'
> #En determinadas ocasiones tendremos problemas para realizar conexiones
> #Por ello en este caso descargo el archivo y lo compio en el PC
> datos<-read.table("c:/temp/GRADES.TXT")
Con la función read.table leemos archivos de distintos orígenes. La ayuda de esta función nos ofrece:
read.table(file, header = FALSE, sep = "", quote = "\"'",
dec = ".", row.names, col.names,
as.is = !stringsAsFactors,
na.strings = "NA", colClasses = NA, nrows = -1,
skip = 0, check.names = TRUE, fill = !blank.lines.skip,
strip.white = FALSE, blank.lines.skip = TRUE,
comment.char = "#",
allowEscapes = FALSE, flush = FALSE,
stringsAsFactors = default.stringsAsFactors(),
encoding = "unknown")read.csv(file, header = TRUE, sep = ",", quote="\"", dec=".",
fill = TRUE, comment.char="", ...)read.csv2(file, header = TRUE, sep = ";", quote="\"", dec=",",
fill = TRUE, comment.char="", ...)read.delim(file, header = TRUE, sep = "\t", quote="\"", dec=".",
fill = TRUE, comment.char="", ...)read.delim2(file, header = TRUE, sep = "\t", quote="\"", dec=",",
fill = TRUE, comment.char="", ...)
Para leer archivos Excel podemos emplear el módulo xlsReadWrite que nos podremos descargar de http://treetron.googlepages.com/ lo instalamos en la librería library de la instalación de R y ya podemos cargarlo y trabajar con la función read.xls:
read.xls( file,
colNames = TRUE,
sheet = 1,
type = "data.frame",
from = 1,
rowNames = NA, colClasses = NA, checkNames = TRUE,
dateTimeAs = "numeric",
stringsAsFactors = default.stringsAsFactors() )
Volviendo al ejemplo con el que estamos trabajando, hemos generado el objeto datos como lectura de un fichero de texto sin cabeceras, será necesario asignarles cabeceras:
> colnames(datos)
[1] "V1" "V2" "V3" "V4" "V5" "V6" "V7" "V8"
> nombres<-c("ID","sexo","clase","test","exam1","exam2","labo","final")
> names(datos) <- nombres #Asignamos nombres
> colnames(datos)
[1] "ID" "sexo" "clase" "test" "exam1" "exam2" "labo" "final"
Creamos un modelo en el que la nota final será nuestra variable dependiente y las notas del resto nuestras variables regresoras:
> ejemplo9.2<-lm(final~test+exam1+exam2+labo,data=datos)
> summary(ejemplo9.2)Call:
lm(formula = final ~ test + exam1 + exam2 + labo, data = datos)Residuals:
Min 1Q Median 3Q Max
-75.5711 -10.5697 0.7903 15.8257 32.6372
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -17.8277 50.2996 -0.354 0.72471
test 0.8606 0.7650 1.125 0.26672
exam1 0.6709 0.2413 2.781 0.00795 **
exam2 0.4316 0.3667 1.177 0.24547
labo 0.2924 0.6182 0.473 0.63855
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 21.06 on 44 degrees of freedom
Multiple R-squared: 0.4716, Adjusted R-squared: 0.4236
F-statistic: 9.818 on 4 and 44 DF, p-value: 9.142e-06
Vemos que sólo se rechaza la hipótesis de nulidad del parámetro para la variable exam1. Es la única que debería formar parte de nuestro modelo. Es evidente que ha de haber una alta correlación entre las variables regresoras, tenemos un problema de multicolinealidad. Para analizarlo vemos la matriz de correlaciones:
> attach(datos)
> cor(data.frame(clase,test,exam1,exam2,labo))
clase test exam1 exam2 labo
clase 1.0000000 0.1456783 0.10696162 0.1532966 0.18110770
test 0.1456783 1.0000000 0.53264951 0.4862278 0.60078608
exam1 0.1069616 0.5326495 1.00000000 0.5215269 0.03359389
exam2 0.1532966 0.4862278 0.52152685 1.0000000 0.23724698
labo 0.1811077 0.6007861 0.03359389 0.2372470 1.00000000
> detach(datos)
Para hacer la matriz de correlaciones empleamos la función cor pero sólo “atacamos” a los campos numéricos de nuestra matriz de datos. Si hacemos:
> cor(datos)
Error en cor(datos) : observaciones perdidas en cov/cor
Además: Warning message:
In cor(datos) : NAs introducidos por coerción
Esto es debido a que tenemos observaciones carácter, la función cor nos devuelve un error. No se detectan relaciones lineales muy fuertes entre las variables. El problema de la multicolinealidad viene por alguna relación lineal entre combinaciones de variables.