El análisis de supervivencia es uno de los olvidados por el Machine Learning y la nueva forma de ver el oficio. A la regresión logística si la damos algo de recorrido porque aparece en scikit-learn (con sus cositas), sin embargo, el análisis de supervivencia no tiene ese cartel porque en el momento que trabajas con un gran número de variables estos modelos «empiezan a echar chispas». Sin embargo ofrecen una serie de gráficos y resultados que más allá de la estimación nos describen problemas y pueden servirnos para segmentar poblaciones en base a la duración hasta la ocurrencia de un evento.
El modelo de supervivencia tiene como variable fundamental el tiempo hasta que ocurre un evento y como este tiempo se modifica en base a unas variables explicativas, mas allá de una tasa nos puede permitir identificar segmentos y poblaciones con comportamientos distintos. El ejemplo que quiero mostraros es el paradigma de todo lo que estoy contando, identificar segmentos de clientes que abandonan mi compañía de telecomunicaciones, mas allá de priorizar clientes en base a su probabilidad de anulación tratamos de identificar características que hacen que mi cliente dure más o menos en la compañía.
El ejemplo que vamos a usar está sacado de este:
https://github.com/zangell44/survival-analysis-lifeline-basics/blob/master/customer_churn.ipynb
Tenéis la descripción de las variables, la más importante es tenure, tiempo en meses hasta que se produce el evento y churn que es el evento, la cancelación de la línea, el resto de variables son propias de la línea. En nuestro caso vamos a trabajar con R porque me parecen interesantes los objetos que generan algunas funciones. Leemos los datos y realizamos una pequeña transformación sobre la variable respuesta:
datos <- read.csv('https://raw.githubusercontent.com/treselle-systems/customer_churn_analysis/master/WA_Fn-UseC_-Telco-Customer-Churn.csv')
datosChurn <- as.integer(ifelse(datosChurn=="Yes",1,0))
Las librerías de R que vamos a usar son survival y survminer:
library(survival) library(survminer)
No nos centramos mucho en la modelización, hacemos lo más sencillo, con la función de supervivencia de Kaplan – Meier estudiamos la duración de las líneas de mi compañía:
KM <- survfit(Surv(tenure, Churn)~1, data = datos)
ggsurvplot(KM, risk.table = TRUE, main = "Tiempo hasta baja del contrato", xlab = "Meses",
ylab = "Tasa")

Estos datos son los primeros que he encontrado buceando por Google, pero con datos reales se aprecian perfectamente los escalones debidos a los compromisos de permanencia en las compañías de teleco, algo que pone especialmente cariñosas a las áreas de negocio, recordad, siempre hemos de empezar por dar cariño a los usuarios de nuestro trabajo, no somos divos. Esto es lo que pasa en el total de nuestra cartera, ¿qué sucede si vamos creando grupos?
KM2 <- survfit(Surv(tenure, Churn)~MultipleLines, data = datos)
ggsurvplot(KM2, conf.int = T, main = "Tiempo hasta baja del contrato", xlab = "Meses", ylim = c(0.6, 1),
ylab = "Tasa")
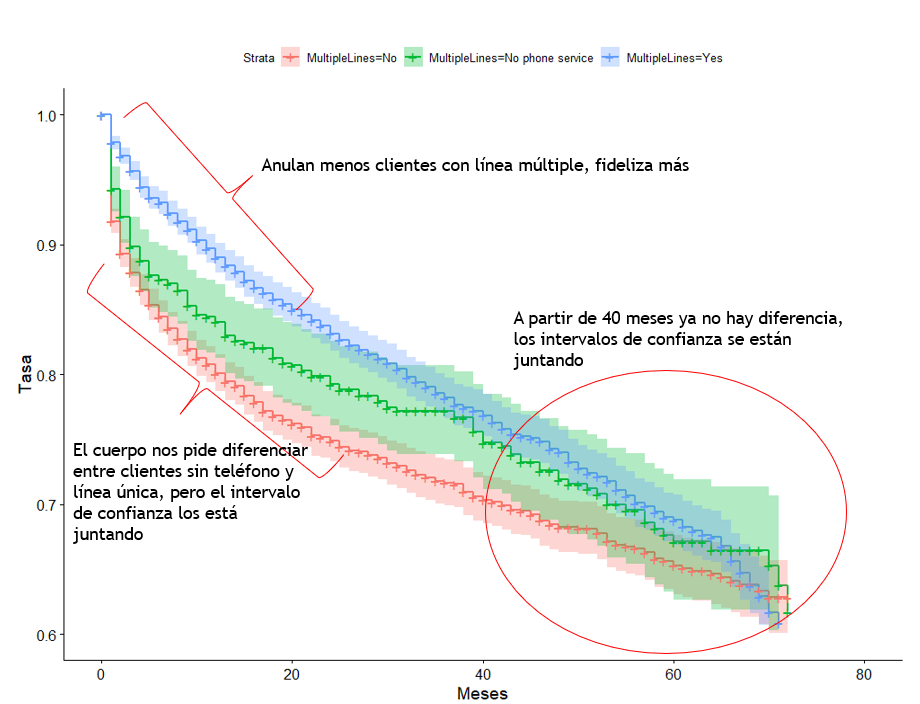
Fijaos todo lo que nos está diciendo este gráfico, los intervalos de confianza son fundamentales y comenzamos a ver resultados. Fideliza mas tener múltiples líneas, pero sólo hasta los 24 meses y a los 40 meses esta variable ya pierde efecto. Por otro lado si nos quedamos sólo con las estimaciones encontraríamos diferencias entre clientes sin teléfono y línea única, sin embargo, los intervalos de confianza se están juntando, el rojo se llega a mezclar con el verde, hay que tener mucho cuidado con las conclusiones que sacamos sobre esos segmentos.
La vida es maravillosa cuando tenemos una variable, imaginemos que metemos 2 variables, los segmentos a analizar se multiplican:
KM3 <- survfit(Surv(tenure, Churn)~MultipleLines+PaymentMethod, data = datos)
ggsurvplot(KM3, conf.int = T,main = "Tiempo hasta baja del contrato", xlab = "Meses", ylim = c(0, 1),
ylab = "Tasa")

Sólo 2 variables y la cosa se va complicando mucho pero observad ese segmento que ha localizado el modelo, tiene una anulación muy alta a partir de los 12 meses. Pero el gráfico es ilegible y obtenemos intervalos enormes, es imposible determinar otros segmentos. Y si nuestro modelo es:
KM4 <- survfit(Surv(tenure, Churn)~MultipleLines+PaymentMethod+InternetService, data = datos) ggsurvplot(KM4, main = "Tiempo hasta baja del contrato", xlab = "Meses", ylim = c(0, 1), ylab = "Tasa")
IMPOSIBLE. Pero KM4 es un objeto muy interesante, planteando una transformación sobre él vamos a crear un data frame con información:
df <- data.frame(tiempos = KM4strata) dfsegmento <- rownames(df) rownames(df)=NULL df <- df[rep(row.names(df), dftiempos), 1:2] df<- cbind.data.frame(df, KM4n.risk, KM4n.event, KM4n.censor, KM4surv, KM4std.err )
strata contiene el nombre de los estratos, cada segmento tiene el número de veces que se repite, con rep reproducimos tantas veces ese segmento como número de veces se produce la repetición y pasamos de 28 registros a los 1.658 resultantes de todas las combinaciones que aparecen. Hemos creado un data frame que contiene los segmentos al que podemos ir añadiendo más elementos de KM4… ¿Y si hacemos un análisis cluster sobre el objeto resultante?
Para hacer este tipo de análisis hay que iterar constantemente con los equipos de negocio, es necesario crear agrupaciones previas y todo es manual, esto no es AutoML, es más sencillo meter todo en una máquina y que salga cada cliente priorizado. Y planteo la siguiente reflexión ¿es más personalizado meter al cliente en la coctelera y etiquertarle con un número o iterar con grupos de clientes y productos? Cada uno verá las cosas de una manera.
Muy interesante Raúl. Recuerdo un análisis de randomforest survival de Pedro para temas de churn . Este tipo de análisis ayudan mucho a conocer tus datos. Como dices, es más cómodo usar «automl» pero creo que el conocimiento del problema que se adquiere utilizando cosas como el análisis de supervivencia ayuda para otros tipos de análisis